
포스팅은 CloudNet@팀 서종호(Gasida)님이 진행하시는
AWS EKS Workshop Study 내용을 참고하여 작성합니다.

안녕하세요!
파드 스케줄링 실습을 하기 위해
Prometheus, Grafana 등 모니터링 도구 소개하고
설치하는 시간을 가져보도록 하겠습니다.

01. Prometheus 소개 및 설치
프로메테우스란? 시계열 데이터베이스 기반의 오픈소스 모니터링 시스템 입니다.
클러스터 / 애플리케이션의 매트릭을 수집하고, 저장하고, 쿼리할 수 있습니다.
📌 특징
- Pull 방식 수집
- 대부분의 모니터링 시스템은 에이전트가 서버로 데이터를 Push하는 방식임.
- 하지만 프로메테우스는 반대로 주기적으로 대상을 직접 Scrape 하는 방식입니다.
Prometheus ──── HTTP GET /metrics ────→ 대상 (파드, 노드, 서비스...)
←── 메트릭 응답 ──────────덕분에 "어떤 대상을 수집할지"를 프로메테우스 쪽에서 중앙 관리를 할 수 있습니다.
- 메트릭 형식 - 텍스트 기반
- 메트릭 이름 + 라벨(key=vaule) + 값으로 구성됨.
- /metrics 엔드포인트에 이 형식으로 노출하면 프로메테우스가 수집이 가능하다.
# HELP http_requests_total Total number of HTTP requests
# TYPE http_requests_total counter
http_requests_total{method="GET", status="200"} 1234
http_requests_total{method="POST", status="500"} 7
- 시계열 데이터베이스 (TSDB)
- 수집한 메트릭을 시간 축으로 저장합니다.
- 기본 스크레이프 간격은 15초, 데이터는 로컬 디스크에 저장되고, 기본 보존 기간은 15일 입니다.
http_requests_total{method="GET"} @ 14:00:00 → 1000
http_requests_total{method="GET"} @ 14:00:15 → 1023
http_requests_total{method="GET"} @ 14:00:30 → 1051
그렇다면 k8s에서 수집 대상을 프로메테우스가 어떻게 알까?
위 특징을 풀어서 생각해보면 프로메테우스의 아키텍쳐를 알 수 있습니다.
Step1. Service Discovery (어디서 긁어올지)
프로메테우스가 수집 대상 목록을 동적으로 파악하는 단계입니다.
k8s 환경에서는 API Server에 계속 질의해서 파드/서비스/노드 목록을 유지합니다.
파드가 새로 생기면 자동으로 수집 대상에 추가되고, 파드가 죽으면 제거됩니다.
Step2. Retrieval / Scrape (긁어오는 것)
Service Deiscovery로 파악한 대상들의 /metrics 엔드포인트에 주기적으로 HTTP GET 요청을 날립니다.
기본은 15초 간격이며, 응답으로 텍스트 형식의 메트릭 데이터가 오면 파싱해서 다음 단계로 넘깁니다.
Step3. TSDB Storage (저장하는 것)
수집한 메트릭을 시계열 데이터베이스에 저장합니다.
메트릭 이름, 라벨, 값, 타임스탬프 조합으로 저장됩니다.
위에서 설명드렸다 싶이 특징은 위와 같으며, 장기 보존이 필요하면 Thanos나 Cortex같은 외부 스토리지로
원격 쓰기(remote write)를 설정할 수 있습니다.
Step4. PromQL / 외부 연동 (꺼내쓰는 것)
저장된 데이터를 PromQL로 쿼리할 수 있는 HTTP API를 노출합니다.
여기에 그라파나가 붙어서 대쉬보드를 그릴 수 있습니다.
Alertmanager는 프로메테우스가 평가한 알림 룰 결과를 받아서 Slack, PagerDuty 같은 곳으로 라우팅할 수 있습니다.
Prometheus Helm 설치
1) Repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
2) helm values 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
additionalScrapeConfigs:
# apiserver metrics
- job_name: apiserver-metrics
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Scheduler metrics
- job_name: 'ksh-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Controller Manager metrics
- job_name: 'kcm-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Enable vertical pod autoscaler support for prometheus-operator
#verticalPodAutoscaler:
# enabled: true
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
📌 additionalScrapeConfigs - EKS 전용 설정
세 가지 job이 있는데, 다 같은 엔드포인트(default/kubernetes/https)를 바라봅니다.
| job | metrics_path | 수집 대상 |
| apiserver-metrics | /metrics(기본) | API Server |
| ksh-metrics | /apis/metrics.eks.amazonaws.com/v1/ksh/... | Kube Scheduler |
| kcm-metrics | /apis/metrics.eks.amazonaws.com/v1/kcm/... | Kube Controller Manager |
Vanilla k8s였으면 Scheduler, Controller Manager에 직접 접근이 가능한데,
EKS는 Control Plane이 AWS 관리형이라 직접 접근이 불가능합니다.
그래서 AWS가 metrics.eks.amazonaws.com API를 별도로 노출해주는 거고, 이걸 통해 우회 수집하는 구조입니다.
그래서 values.yaml 파일 맨 아래 부분에서 모두 false로 수집 방식을 끈 이유가,
kube-prometheus-stack 기본 수집 방식(직접 접근)을 사용하지 않고 additionalScrapeConfigs로
EKS 방식으로 대체한 것 입니다.
3) 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 80.13.3 \
-f monitor-values.yaml --create-namespace --namespace monitoring
4) 배포 확인
배포가 정상적으로 완료가 되었지만, 한번 짚고 넘어가봅시다.

StatefulSet Pods
alertmanager, prometheus 파드가 StatefulSet 파드로 뜬 이유는 데이터를 로컬에 영속 저장하기 때문입니다.
프로메테우스는 TSDB, Alertmanager는 알림 상태를 저장하므로, Deployment로 띄우면
파드 재시작 시 데이터가 날아가니까 StatefulSet으로 띄워졌네요.
DaemonSet Pods
prometheus-node-exporter 파드가 DaemonSet으로 2개가 떠있네요.
모든 노드의 OS 레벨 메트릭(CPU, Memory, Disk, Network)을 수집해야 하니까 각 노드에 1대씩 배치한 것 같습니다.
Deployment
grafana : 시각화 도구, 상태 저장 안해도 되니까 디플로이먼트로 띄워진 것 같습니다.
kube-state-metrics : k8s API를 바라보면서 pods / deployment / node 등
오브젝트 상태를 메트릭으로 변환해주는 exporter.
operator : ServiceMonitor / PodMonitor CRD를 감시하다가 프로메테우스 설정에 자동 반영하는 컨트롤러 입니다.
Service / Endpoint
여기서 주목해야 할 서비스는 prometheus-poerated, alertmanager-opterated 입니다.
ClusterIP가 None으로 되어있네요. 이게 Headless Service 입니다.
StatefulSet 파드에 직접 DNS로 접근할 수 있게 해주는 녀석입니다. (Operator가 StatefulSet 파드를 직접 관리할 때 사용됨)
Endpoint도 전부 파드 IP로 직접 연결된 것이 확인됩니다.

ServiceMonitor / CRD도 아래와 같이 살펴봅시다.
Operator가 프로메테우스 CR을 정상 처리했다는 뜻 입니다.
| ServiceMonitor | 수집 대상 |
| apiserver | API Server |
| kubelet | 각 노드의 kubelet |
| node-exporter | 노드 OS 메트릭 |
| kube-state-metrics | k8s 오브젝트 상태 |
| coredns | DNS 메트릭 |
| grafana / alertmanager / prometheus / operator | 모니터링 스택 자체 메트릭 |
또한 CRD 10개도 정상 등록 됐습니다.
이제 데쉬보드 도메인에 접근해봅시다!

02. EKS 컨트롤 플레인 메트릭을 Prometheus 형식으로 가져오기.
EKS Controle Plane 메트릭 수집 흐름을 관측하는 방법은 4가지가 있습니다.
- CloudWatch Vended Metrics : AWS가 자동으로 올려주는 메트릭 (별도 설정 불필요)
- Prometheus Metrics Endpoint : KCM / KSH 메트릭을 프로메테우스로 수집
- Control Plane Logging : API / Audit 로그를 CloudWatch. Logs로 전송.
- Cluster Insights : 업그레이드 호환성, 헬스 체크 자동 분석
여기서 저희가 하려고 하는 것은 KCM / KSH 메트릭을 수집하는 방식이고,
배포 하기 이전에 additionalScrapeConfigs에서 설명드렸던 것 처럼 EKS라 직접 접근이 불가합니다.
만약, Vanilla k8s였다면?
Prometheus → :10252/metrics (KCM 직접)
Prometheus → :10251/metrics (KSH 직접)EKS는 Control Plane이 AWS관리형이라 이 포트에 직접 접근이 안되서, AWS가 대신 이 API를 노출해줍니다.
/apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics ← Scheduler
/apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics ← Controller Manager이게 eks-extension-metrics-api 서비스를 통해 노출되고, API Service로 등록되어 있습니다.
v1.metrics.eks.amazonaws.com → kube-system/eks-extension-metrics-api AVAILABLE=True프로메테우스는 이 엔드포인트를 통해 우회 수집하게 됩니다.
하지만, 문제가 발생합니다. (SA에 권한이 없거든요)
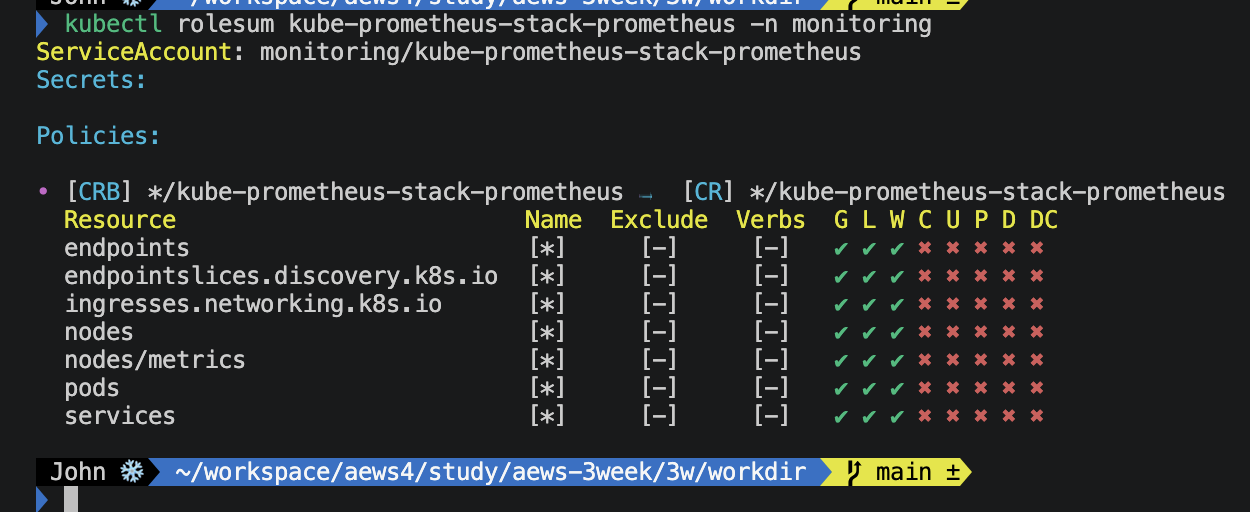
프로메테우스가 저 API를 호출하려면 metrics.eks.amazonaws.com API 그룹에 대한 권한이 있어야 합니다.
이제 SA 권한을 아래와 같이 추가하고, 확인해봅시다.
# ClusterRole에 권한 추가
kubectl patch clusterrole kube-prometheus-stack-prometheus --type=json -p='[
{
"op": "add",
"path": "/rules/-",
"value": {
"verbs": ["get"],
"apiGroups": ["metrics.eks.amazonaws.com"],
"resources": ["kcm/metrics", "ksh/metrics"]
}
}
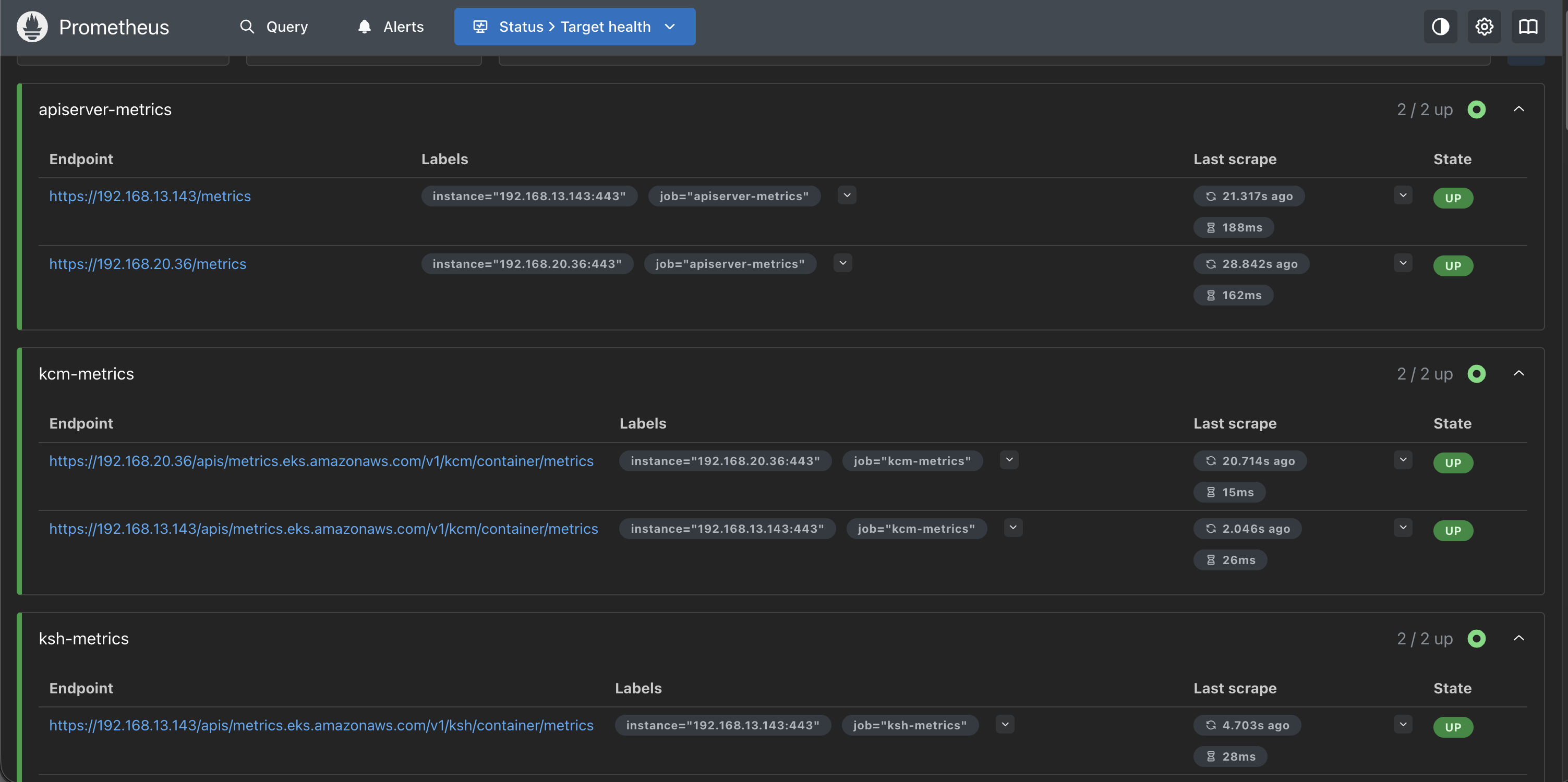
]'KCM, KSH의 메트릭 수집에 대한 권한을 추가해줬고 아래와 같이 확인이 가능합니다.

프로메테우스 Target Health에서도 확인해 보면, kcm과 ksh 메트릭에 대한 상태가 올라왔습니다.
03. Grafana Dashbord 추가
prometheus 스택을 Helm chart로 설치하였을 때 기본적으로 깔린 데쉬보드는 아래와 같습니다.
- 클러스터 리소스 사용량
- 노드 메트릭
- 워크로드 별 리소스
- CoreDNS, kubelet 등..
하지만 values.yaml 파일에서 additionalScrapeConfigs 부분을 참고해 보시면
API Server 메트릭을 수집하도록 설정을 하였습니다. 이것을 시각화 할 대쉬보드를 추가해볼까요?
1) 데쉬보드 다운로드
curl -O https://raw.githubusercontent.com/dotdc/grafana-dashboards-kubernetes/refs/heads/master/dashboards/k8s-system-api-server.json
2) sed 명령어로 uid 일괄 변경
sed -i -e 's/${DS_PROMETHEUS}/prometheus/g' k8s-system-api-server.json기본 데이터 소스의 uid 'prometheus'를 사용하게 변경합니다.
3) my-dashboard Configmap 생성
kubectl create configmap my-dashboard --from-file=k8s-system-api-server.json -n monitoring
kubectl label configmap my-dashboard grafana_dashboard="1" -n monitoringGrafana 파드 내의 사이드카 컨테이너가 grafana_dashboard="1"로 라벨을 탐지하게 설정.
4) 데쉬보드 경로에 추가 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- ls -l /tmp/dashboards
5) Grafana 데쉬보드 확인 - API Server 수집


추가가 완료된 것을 확인할 수 있습니다.
동작 흐름을 재 확인 해보자면 아래와 같습니다.
kubectl label configmap my-dashboard grafana_dashboard="1"
↓
grafana sidecar가 라벨 감지 (watch 중)
↓
ConfigMap의 JSON을 /tmp/dashboards/에 복사
↓
Grafana가 파일 읽어서 대시보드 등록
04. 도전과제
위 vaules.yaml 설정의 additionalScrapeConfigs 부분을 응용하여 프로메테우스에서
다른 메트릭을 가져올 수 있도록 설정을 해보도록 하겠습니다.
kube-prometheus-stack helm 배포 시, eks etcd 메트릭을 가져오기.
아까 vaules 파일에서 etcd 메트릭을 가져오도록 비활성화 된 것을 확인할 수 있습니다.
kubeEtcd:
enabled: falseetcd를 비활성화 한 이유가 계속 언급했던 대로 EKS etcd는 Control Plane이기 때문입니다.
(vanilla k8s는 :2379/metrics로 직접 긁을 수 있는데, EKS는 불가능)
그렇다면 아까 KCM / KSH 때 사용했던 패턴 그대로 metrics.eks.amazonaws.com API를 통해
etcd 메트릭도 노출하게 할 수 있습니다.
📌 additionalScrapeConfigs에 etcd job 추가
monitor-values.yaml을 열어서 kcm-metrics job 아래에 추가해줍시다.

📌 Helm upgrade
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 80.13.3 \
-f monitor-values.yaml \
--namespace monitoring \
--force-conflicts'--force-conflicts' 플래그를 추가해서 Helm이 소유권 강제로 가져오게 해야합니다.
(values.yaml을 우리가 수정하였으므로 force 플래그 없이는 에러 발생)
📌 ClusterRole 권한 부여
kubectl patch clusterrole kube-prometheus-stack-prometheus --type=json -p='[
{
"op": "add",
"path": "/rules/-",
"value": {
"verbs": ["get"],
"apiGroups": ["metrics.eks.amazonaws.com"],
"resources": ["kcm/metrics", "ksh/metrics", "etcd/metrics"]
}
}
]'
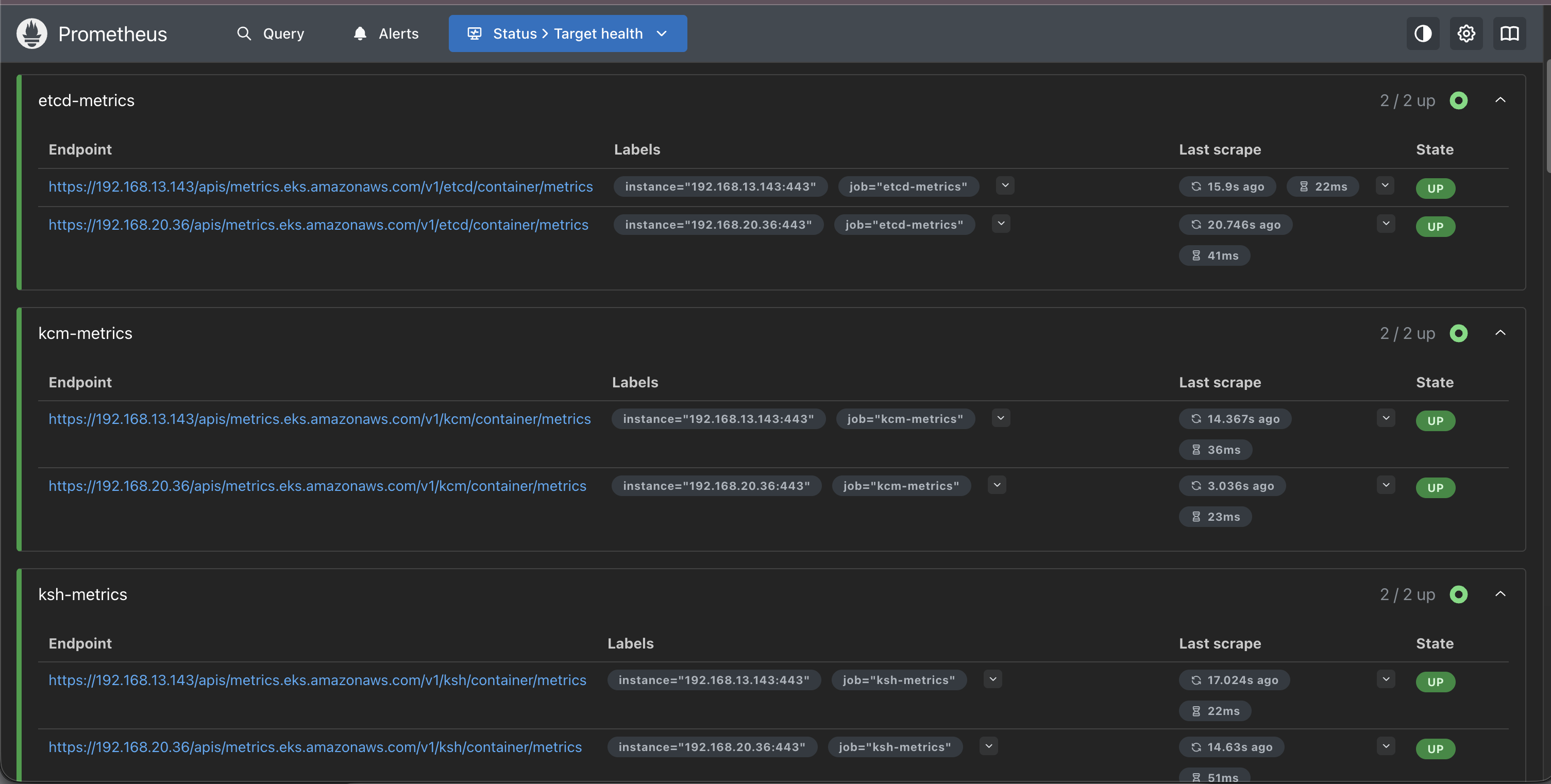
권한을 부여한 후에 확인해보니 etcd에 대한 ClusterRole도 부여가 되었습니다.

실제로 프로메테우스 Target Health에서도 아래와 같이 'etcd-metrics'을 확인 가능합니다.
kube-prometheus-stack helm 배포 시, Grafana에 대시보드(kcm, scheduler) 링크를 추가하여 배포
그라파나 대시보드를 Helm 배포 시 자동으로 포함시키려면 두 가지 방법이 있습니다.
방법1) grafana.com 대시보드의 ID를 vaules.yaml에 참조시키는 방식
방법2) grafana에서 api-server 메트릭을 수집하기 위해 직접 JSON으로 다운로드한 방식
해당 내용에서는 방법 1을 사용하여 구현을 해보도록 하겠습니다.
그전에, gnetID가 하는 일에 대해서 알아야 합니다.
gnetID란 grafana.com/grafana/dashboards에 올라와 있는 커뮤니티 대시보드의 고유 ID 입니다.
Helm 배포 시 그라파나 파드가 뜨면서 이 URL로 JSON을 자동 다운로드 해옵니다.
그라파나 파드 기동
↓
grafana.com/api/dashboards/11964 에 HTTP 요청
↓
JSON 다운로드
↓
/var/lib/grafana/dashboards/default/ 에 저장
↓
대시보드 자동 등록grafana에서 KCM(Kubernetes Controller Manager)을 모니터링 하기 위해 많이 사용되는 gnetID는 12122 입니다.
grafana에서 Scheduler를 모니터링하기 위한 대표적인 gnetID는 12663 입니다.
이 부분을 확인하여 values.yaml을 수정하면 됩니다.
기존 grafana: 섹션에서 dashboardProvider, dashboards 블록을 추가하고,
위 gnetID는 vanilla k8s 기준이여서 EKS 기준으로 맞추기 위해선 job_name도 수정해야 합니다.
1) job_name 수정
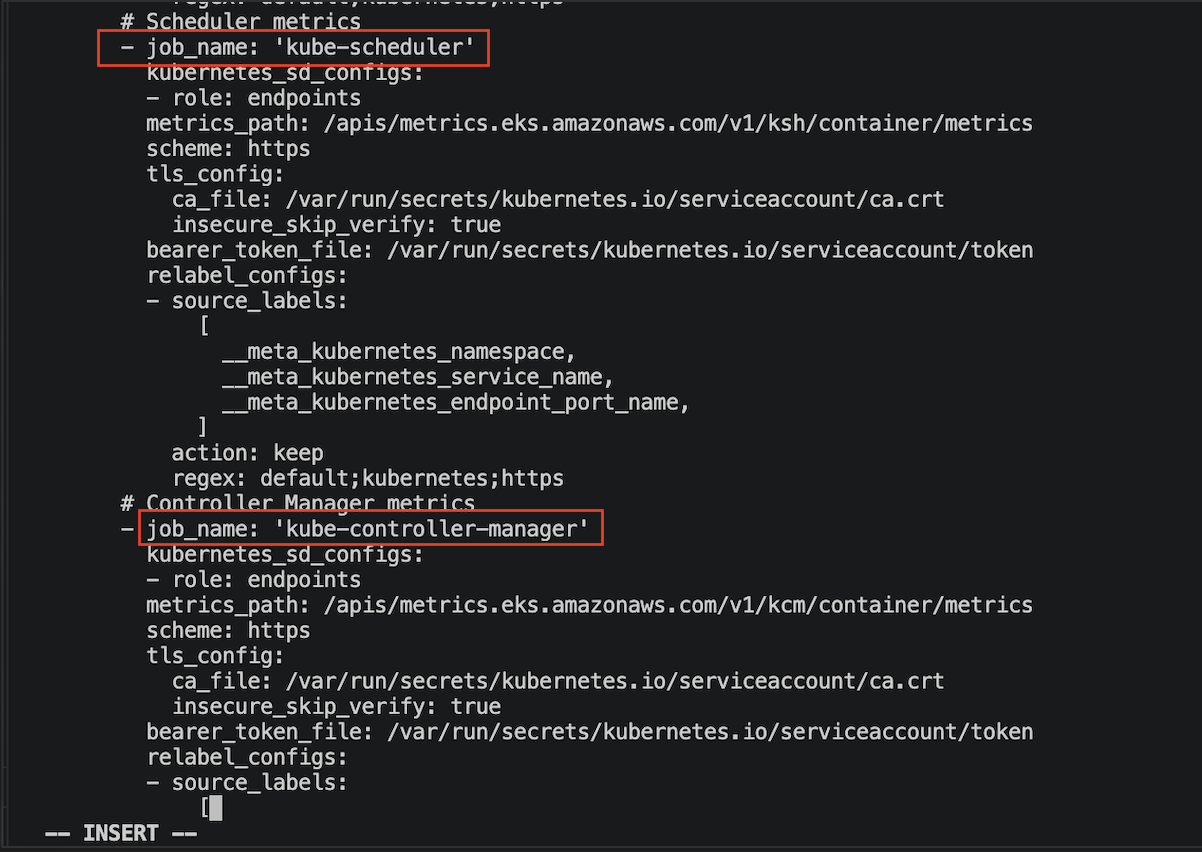
ksh-metrics을 'kube-scheduler'로 변경
kcm-metrics을 'kube-controller-manager'로 변경
2) dashboardProvider, dashboards 블록 추가

그 다음 helm upgrade:
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 80.13.3 \
-f monitor-values.yaml \
--namespace monitoring \
--force-conflicts
마지막으로 ClusterRole 부여:
'--force' 플래그로 upgrade를 하면 Helm이 ClusterRole을 기본값으로 덮어써서 권한이 날라갑니다.
kubectl patch clusterrole kube-prometheus-stack-prometheus --type=json -p='[
{
"op": "add",
"path": "/rules/-",
"value": {
"verbs": ["get"],
"apiGroups": ["metrics.eks.amazonaws.com"],
"resources": ["kcm/metrics", "ksh/metrics", "etcd/metrics"]
}
}
]'
ClusterRole 확인:

그라파나 대쉬보드 확인:

해당 이슈는 아래에서 더 다루도록 하겠습니다.
EKS 전용 Grafana 커스텀 대시보드 생성
위 방법대로 진행을 하였어도 vanilla k8s와 메트릭 명이 달라서 실제로 제대로 수집이 되지 않았다.
그래서 grafana 대쉬보드 ID를 vaules.yaml에 참조하는 방식은 다음에 딥다이브하게 다뤄보도록 하고,
결국 실제 수집된 메트릭 기반으로 커스텀 대시보드 JSON을 만들어 보기로 하였습니다.

윗 부분이 실제 EKS에서 수집되는 메트릭이고, 아래가 대시보드가 기대하는 메트릭 입니다.
대시보드 gnetID 12663도 구버전 vanilla k8s 기준이라 매트릭명 자체가 안맞습니다.
📌 eks-scheduler-dashboard.json 파일 생성
{
"title": "EKS / Kube Scheduler",
"uid": "eks-kube-scheduler",
"timezone": "Asia/Seoul",
"schemaVersion": 38,
"version": 1,
"refresh": "30s",
"panels": [
{
"id": 1,
"title": "Scheduler Up",
"type": "stat",
"gridPos": { "x": 0, "y": 0, "w": 4, "h": 4 },
"targets": [
{
"datasource": "prometheus",
"expr": "sum(up{job=\"kube-scheduler\"})",
"legendFormat": "Up"
}
],
"options": {
"colorMode": "background",
"graphMode": "none",
"textMode": "auto"
},
"fieldConfig": {
"defaults": {
"thresholds": {
"steps": [
{ "color": "red", "value": 0 },
{ "color": "green", "value": 1 }
]
},
"mappings": []
}
}
},
{
"id": 2,
"title": "Scheduling Attempts (success/error/unschedulable)",
"type": "timeseries",
"gridPos": { "x": 4, "y": 0, "w": 20, "h": 8 },
"targets": [
{
"datasource": "prometheus",
"expr": "sum(rate(scheduler_schedule_attempts_total{job=\"kube-scheduler\", result=\"scheduled\"}[5m]))",
"legendFormat": "scheduled"
},
{
"datasource": "prometheus",
"expr": "sum(rate(scheduler_schedule_attempts_total{job=\"kube-scheduler\", result=\"error\"}[5m]))",
"legendFormat": "error"
},
{
"datasource": "prometheus",
"expr": "sum(rate(scheduler_schedule_attempts_total{job=\"kube-scheduler\", result=\"unschedulable\"}[5m]))",
"legendFormat": "unschedulable"
}
],
"fieldConfig": {
"defaults": {
"unit": "ops",
"custom": { "lineWidth": 2 }
}
}
},
{
"id": 3,
"title": "Pending Pods (active)",
"type": "stat",
"gridPos": { "x": 0, "y": 4, "w": 4, "h": 4 },
"targets": [
{
"datasource": "prometheus",
"expr": "sum(scheduler_pending_pods{job=\"kube-scheduler\", queue=\"active\"})",
"legendFormat": "active"
}
],
"fieldConfig": {
"defaults": {
"thresholds": {
"steps": [
{ "color": "green", "value": 0 },
{ "color": "yellow", "value": 10 },
{ "color": "red", "value": 50 }
]
}
}
}
},
{
"id": 4,
"title": "Pending Pods by Queue",
"type": "timeseries",
"gridPos": { "x": 0, "y": 8, "w": 12, "h": 8 },
"targets": [
{
"datasource": "prometheus",
"expr": "sum(scheduler_pending_pods{job=\"kube-scheduler\", queue=\"active\"})",
"legendFormat": "active"
},
{
"datasource": "prometheus",
"expr": "sum(scheduler_pending_pods{job=\"kube-scheduler\", queue=\"backoff\"})",
"legendFormat": "backoff"
},
{
"datasource": "prometheus",
"expr": "sum(scheduler_pending_pods{job=\"kube-scheduler\", queue=\"unschedulable\"})",
"legendFormat": "unschedulable"
},
{
"datasource": "prometheus",
"expr": "sum(scheduler_pending_pods{job=\"kube-scheduler\", queue=\"gated\"})",
"legendFormat": "gated"
}
],
"fieldConfig": {
"defaults": {
"unit": "short",
"custom": { "lineWidth": 2 }
}
}
},
{
"id": 5,
"title": "Scheduling Attempt Duration (p50/p90/p99)",
"type": "timeseries",
"gridPos": { "x": 12, "y": 8, "w": 12, "h": 8 },
"targets": [
{
"datasource": "prometheus",
"expr": "histogram_quantile(0.50, sum(rate(scheduler_scheduling_attempt_duration_seconds_bucket{job=\"kube-scheduler\"}[5m])) by (le))",
"legendFormat": "p50"
},
{
"datasource": "prometheus",
"expr": "histogram_quantile(0.90, sum(rate(scheduler_scheduling_attempt_duration_seconds_bucket{job=\"kube-scheduler\"}[5m])) by (le))",
"legendFormat": "p90"
},
{
"datasource": "prometheus",
"expr": "histogram_quantile(0.99, sum(rate(scheduler_scheduling_attempt_duration_seconds_bucket{job=\"kube-scheduler\"}[5m])) by (le))",
"legendFormat": "p99"
}
],
"fieldConfig": {
"defaults": {
"unit": "s",
"custom": { "lineWidth": 2 }
}
}
},
{
"id": 6,
"title": "Preemption Attempts",
"type": "timeseries",
"gridPos": { "x": 0, "y": 16, "w": 12, "h": 8 },
"targets": [
{
"datasource": "prometheus",
"expr": "sum(rate(scheduler_preemption_attempts_total{job=\"kube-scheduler\"}[5m]))",
"legendFormat": "preemption attempts/s"
}
],
"fieldConfig": {
"defaults": {
"unit": "ops",
"custom": { "lineWidth": 2 }
}
}
},
{
"id": 7,
"title": "Preemption Victims (p50/p99)",
"type": "timeseries",
"gridPos": { "x": 12, "y": 16, "w": 12, "h": 8 },
"targets": [
{
"datasource": "prometheus",
"expr": "histogram_quantile(0.50, sum(rate(scheduler_preemption_victims_bucket{job=\"kube-scheduler\"}[5m])) by (le))",
"legendFormat": "p50"
},
{
"datasource": "prometheus",
"expr": "histogram_quantile(0.99, sum(rate(scheduler_preemption_victims_bucket{job=\"kube-scheduler\"}[5m])) by (le))",
"legendFormat": "p99"
}
],
"fieldConfig": {
"defaults": {
"unit": "short",
"custom": { "lineWidth": 2 }
}
}
}
],
"templating": { "list": [] },
"annotations": { "list": [] },
"time": { "from": "now-1h", "to": "now" }
}
📌 ConfigMap & labels 생성 및 부착
kubectl create configmap eks-scheduler-dashboard \
--from-file=eks-scheduler-dashboard.json -n monitoring
kubectl label configmap eks-scheduler-dashboard \
grafana_dashboard="1" -n monitoring
그라파나 대쉬보드를 아래와 같이 구성을 완료하였습니다.

적용된 패널은 아래와 같습니다.
| 패널 | 설명 |
| Scheduler Up | 현재 스케줄러가 몇 대 살아있는지. EKS HA라 2가 정상 |
| Scheduling Attempts | 초당 파드 스케줄링 성공/실패/배치불가 횟수 |
| Pending Pods (active) | 현재 스케줄링 대기 중인 파드 수 |
| Pending Pods by Queue | 대기 파드를 큐 종류별로 분류 — active(대기중), backoff(재시도 대기), unschedulable(배치 불가), gated(게이팅됨) |
| Scheduling Duration p50/p90/p99 | 파드 1개 스케줄링하는데 걸리는 시간 분포. p99가 높으면 클러스터 부하 신호 |
| Preemption Attempts | 높은 우선순위 파드 배치를 위해 기존 파드를 쫓아낸 횟수 |
| Preemption Victims p50/p99 | 한 번 선점 이벤트에서 쫓겨난 파드 수 분포 |
⚠️ 실습 환경 삭제 절차
# 프로메테우스-스택 삭제
helm uninstall -n monitoring kube-prometheus-stack
# kube-ops-view 삭제
kubectl delete ingress -n kube-system kubeopsview
helm uninstall kube-ops-view --namespace kube-system
# 테라폼으로 삭제
terraform destroy -auto-approve
긴 글 읽어주셔서 감사합니다.
다음 내용은 EKS 관리형 노드그룹 및 Scaling Up에 대해서 소개하도록 하겠습니다