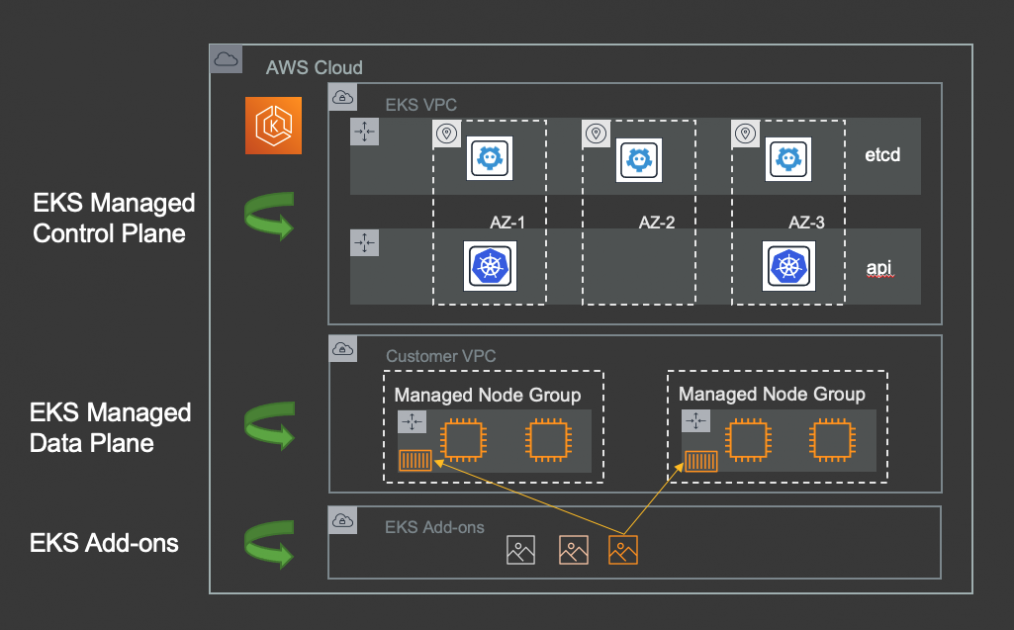
Introduce
·
About Me
안녕하세요,간단하게 제 소개를 드리도록 하겠습니다 :) Let me introduce myself.클라우드 인프라 운영에 관심을 가지고 공부한 기술들을 공유하고자 Blog를 개설하게 되었으며현재 외국계 기업에서 IT Cloud Engineer 직무를 맡고 있고 AWS와 Azure 벤더 중심으로 운영하고 있습니다. 👨💻 Experiences네트워크 엔지니어 | 기술1팀 | 팀원 2021.06 ~ 2023.07Cisco 벤더사의 L2 Switching, L3 Routing, Wireless 구축 및 운용FortiGate, Axgate, Cisco ASA 등 방화벽을 활용한 IPSec VPN, SSL VPN 구축 및 Policy 운영네트워크 인프라 구축 및 고객사 인프라 유지보수 클라우드 엔지니..