Just-in-time Nodes for Any Kubernetes Cluster : Karpenter
포스팅은 CloudNet@팀 서종호(Gasida)님이 진행하시는
AWS EKS Workshop Study 내용을 참고하여 작성합니다.
안녕하세요!
오늘은 노드 수를 스케일링 해주는 도구 두번째 편
Karpenter에 대해서 소개해보도록 하겠습니다.
한번 CA와 비교해보면서 실습해도 좋을 것 같습니다 ~

01. introduct to Karpenter
Karpenter는 AWS가 개발한 고성능 지능형 Kubernetes 컴퓨팅 프로비저닝 솔루션입니다.
Cluster Autoscaler(CA)와 비교했을 때 가장 큰 차이점은 속도와 지능이에요.
CA는 노드 그룹(ASG) 단위로 스케일링하고, 어떤 인스턴스 타입을 쓸지는 미리 정의된 노드 그룹에 의존합니다.
반면, Karpenter는 pending pod의 resource request를 직접 분석해서 최적의 인스턴스 타입을 실시간으로 선택하고,
EC2 Fleet API를 통해 직접 인스턴스를 프로비저닝 합니다.
그 결과 노드 기동 시간이 수십 초 단위로 줄어들어요.
📌 핵심 특징 3가지
- 지능형 동적 인스턴스 선택: Spot, On-Demand, Graviton(arm64) 등을 워크로드 요구사항에 맞게 자동 선택
- 자동 워크로드 Consolidation: 낭비되는 노드를 감지하고 재배치해서 비용 최적화
- 빠른 노드 기동: CA 대비 훨씬 짧은 provisioning latency
📌 동작 방식

Kubernetes 스케줄러(sched)는 pending pod를 기존 노드(Existing capacity)에 먼저 배치하려 합니다.
하지만, 기존 노드에 자원이 부족하면 pod는 Unschedulable 상태가 되겠죠?
여기서 Karpenter가 아래와 같이 개입합니다.
이 unschedulable pod들의 resource request, nodeSelector, affinity, toleration 같은
Kubernetes 네이티브 스케줄링 제약사항 을 그대로 읽어서,
딱 맞는 인스턴스 타입을 Just-in-time으로 프로비저닝합니다.
CA와 달리 별도의 노드 그룹 설정 없이 Provisioner 리소스 하나로 인스턴스 선택 범위를 정의한다는 게 포인트 !
추가적으로 노드 그룹을 거치지 않아서 Hop count도 하나를 더 소모하지 않게 되므로 속도 측면에서도 빠릅니다.
📌 Consolidation

시간이 지나면 클러스터엔 아래와 같은 상황이 생깁니다:
노드는 여러 개 떠 있는데 실제 pod는 듬성듬성 올라가 있는 상태. 이게 비용 낭비로 직결됩니다.
Karpenter의 Consolidation 기능은 두 가지로 동작합니다.
- Pod 재스케줄링: 사용률 낮은 노드의 pod를 다른 기존 노드로 옮기고, 빈 노드를 종료
- 노드 교체: 현재 노드보다 더 저렴한 인스턴스로 교체 가능하면, 기존 노드를 종료하고 더 싼 노드를 새로 띄움
결과적으로 여러 개의 분산된 노드가 최적화된 소수의 노드로 압축되어 비용 효율 + 최적화 1석 2조 입니다.
📌 Consolidation 동작 방식
Karpenter는 poll 주기마다 아래 순서로 동작합니다:
- Consolidation poll 주기 대기 : 매 루프마다 일정 간격으로 실행합니다.
- 대상 노드 식별 : 다음 세 조건을 모두 만족해야 Consolidation 후보가 됩니다.
- Consolidation이 활성화된 Provisioner가 만든 노드
- do-not-consolidate 어노테이션이 없는 노드
- 초기화 완료, Ready 상태, 모든 extended resource가 등록된 노드
- 중단 비용(disruption cost) 기준 정렬 : 중단 비용이 낮은 노드부터 처리합니다.
- 중단 비용 : 해당 노드에 올라간 pod의 중요도(PDB, priority), 노드 기동 시간 등을 종합한 지표입니다.
- 스케줄링 시뮬레이션 : 최저 비용 노드를 제거했을 때 pod들이 어디로 갈 수 있는지 시뮬레이션
- 기존 노드에 스케줄 가능 → 노드 삭제
- 더 저렴한 새 노드에 스케줄 가능 → 노드 축소(교체)
- 동일하거나 더 비싼 노드만 가능 → 기존 유지
do-not-consolidate 어노테이션은 특정 노드를 Consolidation 대상에서 제외할 때 쓰는 escape hatch!
예를 들어 stateful 워크로드나 disruption에 민감한 배치 잡이 올라간 노드에 달아두면 됩니다.
📌 관리 간소화

CA에서 Graviton이나 Spot을 쓰려면 각각 별도 노드 그룹을 만들어야 합니다.
amd64 On-Demand, arm64 On-Demand, amd64 Spot, arm64 Spot etc..
조합마다 노드 그룹이 필요하고, 그만큼 관리 복잡도가 올라가겠죠?
하지만 Karpenter는 Provisioner 하나에서 모두 커버 가능합니다.
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64", "arm64"]이 설정만으로 Karpenter는 Spot/On-Demand, x86/Graviton을 모두 후보로 놓고,
워크로드 요구사항과 현재 EC2 가격을 보고 최적의 조합을 자동 선택합니다.
02. Precautions Before Karpenter Practice
Chapter2 에서는 Karpenter를 배포하기 이전에 유의사항에 대해서 다뤄보도록 하겠습니다.
1) Production에서 AMI 고정 (Pin AMI)
Karpenter는 기본적으로 최신 AMI를 자동으로 선택합니다. → Production에서는 문제될 수 있습니다.
신규 AMI로 노드가 교체되면 예상치 못한 커널 변경, 드라이버 변경, 부팅 실패 같은 이슈가 발생할 수 있기 때문에
Production에서는 반드시 검증된 특정 버전으로 고정해야 합니다.
amiSelectorTerms:
- alias: al2023@v20240807이런식으로 날짜 기반 alias로 특정 버전을 pin하는 방식을 사용할 수 있습니다.
Non-Production에서는 최신 버전으로 테스트하다가, 검증되면 Production에 날짜 버전으로 반영하는 흐름으로
운영하게 된다면 보다 안전하게 운영이 가능할 것으로 사료됩니다.
2) Karpenter Controller 배치
Karpenter가 관리하는 노드에 Karpenter 자신이 배치가 된다면 어떻게 될까요?
Karpenter가 Consolidation이나 노드 종료를 트리거했을 때, 자기 자신이 올라간 노드를 삭제해버리면
Controller도 같이 죽어버리는 이슈를 직면할 수 있습니다. → 복구가 안될 수 있음.
그래서, Karpenter Controller를 올릴 수 있는 옵션 2가지는 아래와 같습니다.

옵션1. 소규모 Managed Node Group을 별도로 유지 (최소 1개 worker node)
→ Karpenter가 건드리지 않는 고정 노드로 운영
옵션2. EKS Fargate Profile을 Karpenter namespace에 생성
→ Fargate는 Karpenter가 관리하지 않으니까 안전합니다.
대부분 프로덕션 환경에서는 옵션1을 사용합니다.
Fargate는 콜드 스타트가 있어서 Controller Pod가 재시작 될 때 기동 시간이 예측 불가능하기 때문이죠.
Controller 자체가 클러스터의 핵심 컴포넌트라 응답 속도가 중요한데, Fargate는 그 측면에서 불리합니다.
3) 불필요한 Instance type 제외
Karpenter는 요구사항에 맞는 인스턴스 타입을 굉장히 넓은 범위에서 선택합니다.
근데 실제로는 쓰고 싶지 않은 타입이 있겠죠? 예를 들어 GPU 인스턴스나 과도하게 큰 Graviton 인스턴스.
비용 측면에서도 그렇고, 워크로드 특성상 맞지 않는 인스턴스가 선택되는 걸 막으려면
NotIn operator로 명시적으로 제외해야 합니다.
- key: node.kubernetes.io/instance-type
operator: NotIn
values:
- m6g.16xlarge
- m6gd.16xlarge
- r6g.16xlarge
- r6gd.16xlarge
- c6g.16xlarge특히 대형 Graviton 인스턴스는 arm64 호환 안 되는 이미지가 있으면 문제가 되고,
한 노드에 pod가 너무 많이 몰릴 수 있어서 제외하는 게 일반적입니다.
4) Spot 사용 시 Interruption Handling 활성화
Spot 인스턴스는 AWS가 2분 전에 중단 알림을 줍니다.
2분 안에 pod를 안전하게 이동시켜야 하는데, Karpenter는 이걸 SQS 기반 Interruption Handling으로 처리함.

다이어그램 흐름도를 글로 좀 풀어서 쓰자면 아래와 같습니다:
- AWS가 Spot 중단 이벤트를 SQS Queue로 전송
- Karpenter Controller가 이벤트를 수신
- 영향받는 노드에 Taint 적용 → 신규 pod 스케줄링 차단
- 동시에 신규 노드 프로비저닝 시작 → 대체 노드를 미리 준비
- 기존 노드를 Drain → pod들을 신규 노드로 이전
- 신규 노드 Ready 확인 후 기존 노드 Terminate
핵심은 2분 경고를 받자마자 신규 노드 프로비저닝을 시작한다는 것 입니다.
Drain과 신규 노드 준비를 병렬로 진행하기 때문에 2분 안에 처리가 가능합니다.
이걸 활성화하려면 Karpenter 설치 시 SQS Queue와 EventBridge Rule을 같이 만들어야 합니다!
(Terraform 모듈에서는 enable_spot_termination = true 옵션으로 처리돼요)
03. Getting Started with Karpenter
먼저 실습하기 이전에 아래와 같은 도구들이 사전에 설치되어 있으면 실습이 편해요!
# 설치 방법은 이전 포스팅 글들을 참고해주세요.
aws-cli (+자격 증명 설정)
kubectl
eksctl
helm
eks-node-view
앞으로 계속 사용하게 될 환경변수를 미리 셋팅해두시길 권고드립니다.
# 변수 설정
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.10.0"
export K8S_VERSION="1.34"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="sunghwan-karpenter-demo" # ${USER}-karpenter-demo
export AWS_DEFAULT_REGION="ap-northeast-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
# 확인
echo "${KARPENTER_NAMESPACE}" "${KARPENTER_VERSION}" "${K8S_VERSION}" "${CLUSTER_NAME}" "${AWS_DEFAULT_REGION}" "${AWS_ACCOUNT_ID}" "${TEMPOUT}" "${ALIAS_VERSION}"
출력하였을 때 잘 출력이 되는지 확인해주세요!
Create a Cluster : eksctl
실습 편의 상 Terraform으로 클러스터를 설치하기에 고려할 것이 너무 많아서, eksctl로 진행하겠습니다.
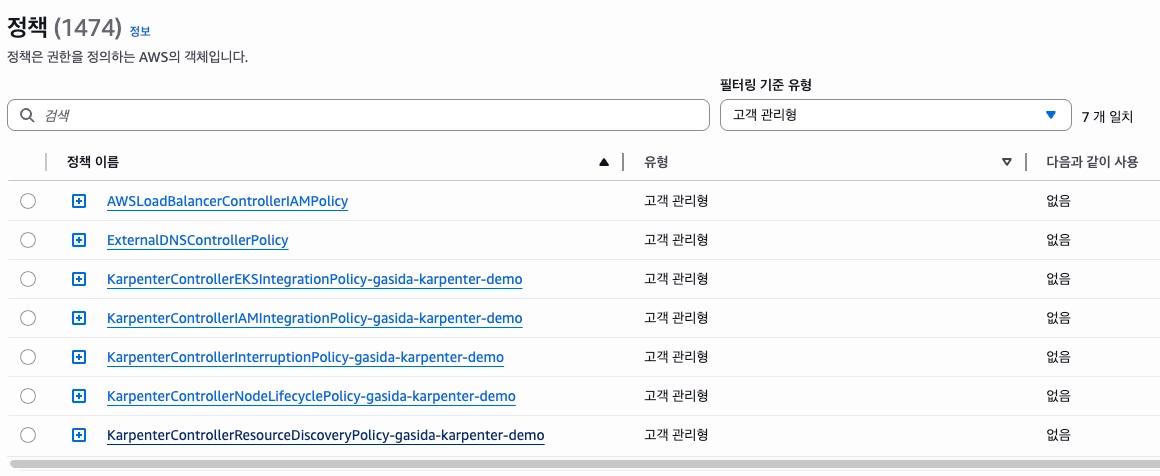
클러스터를 사용하기 위해서는 해당 정책들이 필요한데, CloudFormation에서 자동 생성 해줍니다.
📌 CloudFormation 스택 생성
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > "${TEMPOUT}" \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"아래와 같이 CloudFormation에 Stacks이 자동으로 생성되었는데 확인해볼까요? (총 13개가 생성되었네요)

Stacks으로 생성된 리소스들 중 대표적으로 4가지만 말씀드리도록 하겠습니다.
KarpenterNodeRole : Karpenter가 프로비저닝할 노드용 IAM Role
KarpenterController 5개 Policy : 앞으로 eksctl config에서 참조할 Policy (Pod Identity Associations 정책)
SQS Queue : Spot Interruption Handling용
EventBridge Rules : Spot 중단, instance rebalance, scheduled change 이벤트를 SQS로 라우팅
📌 Create a cluster
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "${K8S_VERSION}"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerNodeLifecyclePolicy-${CLUSTER_NAME}
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerIAMIntegrationPolicy-${CLUSTER_NAME}
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerEKSIntegrationPolicy-${CLUSTER_NAME}
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerInterruptionPolicy-${CLUSTER_NAME}
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerResourceDiscoveryPolicy-${CLUSTER_NAME}
iamIdentityMappings:
- arn: "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
## If you intend to run Windows workloads, the kube-proxy group should be specified.
# For more information, see https://github.com/aws/karpenter/issues/5099.
# - eks:kube-proxy-windows
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2023
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
addons:
- name: eks-pod-identity-agent
EOFcluster yaml 파일의 설정을 한번 살펴보도록 하겠습니다.
1) metadata + tags
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}Karpenter가 어떤 서브넷과 보안 그룹을 사용할지 자동 탐색하는 데 쓰입니다.
EC2NodeClass에서 subnetSelectorTerms, securityGroupSelectorTerms에 이 태그를 참조합니다.
2) iam: podIdentityAssociations
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- ...KarpenterControllerNodeLifecyclePolicy
- ...KarpenterControllerIAMIntegrationPolicy
- ...KarpenterControllerEKSIntegrationPolicy
- ...KarpenterControllerInterruptionPolicy
- ...KarpenterControllerResourceDiscoveryPolicyIRSA 대신 EKS Pod Identity 방식을 쓰고 있네요. Best Practice 최신 방식입니다.
- NodeLifecycle — EC2 인스턴스 생성/삭제/태깅
- IAMIntegration — 노드에 IAM Role 연결 (PassRole)
- EKSIntegration — EKS 클러스터 API 접근
- Interruption — SQS Queue 읽기/삭제 (Spot Interruption Handling)
- ResourceDiscovery — 서브넷, 보안 그룹, AMI 탐색
이 Policy들은 eksctl 실행 전에 미리 생성되어 있어야 합니다 (CloudFormation Stacks으로 배포 완료)
3) iamIdentityMappings
iamIdentityMappings:
- arn: "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
Karpenter가 프로비저닝한 노드가 클러스터에 join할 수 있도록 aws-auth ConfigMap에 등록하는 부분입니다.
이게 없으면 Karpenter가 EC2를 띄워도 노드가 클러스터에 붙지 못해.
4) managedNodeGroups
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2023
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10앞서 얘기한 "Karpenter Controller를 올릴 고정 노드 그룹" 이야.
m5.large 2대로 시작하고 Karpenter가 관리하지 않는 영역입니다.
5) addons: eks-pod-identity-agent
Pod Identity 방식을 쓰려면 이 에이전트가 반드시 설치되어 있어야 합니다.
IRSA는 이게 필요 없는데, Pod Identity는 이 DaemonSet이 각 노드에서 토큰 교환을 처리해줘요.
Verify cluster deployment with eksctl
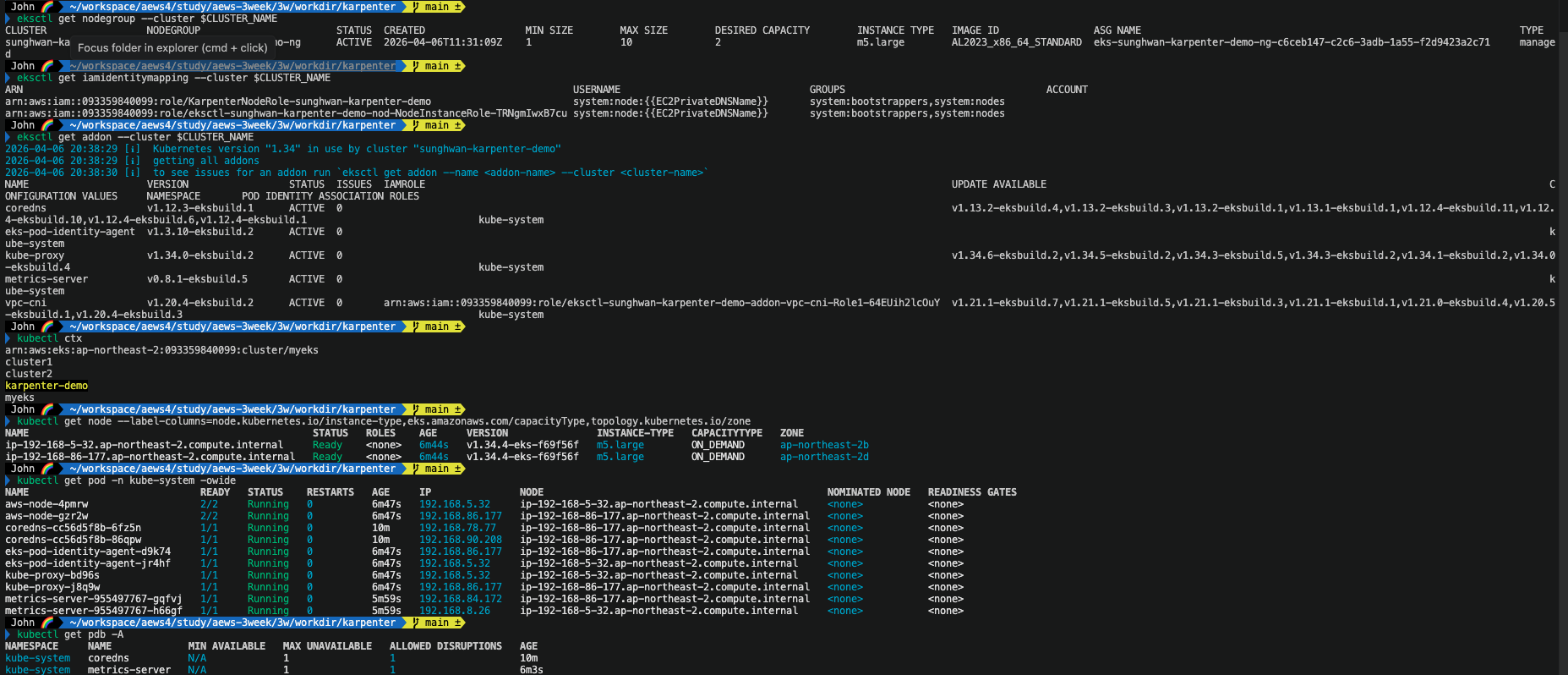
클러스터가 정상적으로 동작하는지 확인해보았습니다.
m5.large / DESIRED 2 / MIN 1 / MAX 10 / AL2023 / ACTIVE고정 노드 그룹 상태가 정상이네요. 이 위에 Karpenter Controller가 올라갈 예정입니다.
iamidentitymapping에 두 개의 Role이 등록되어 있습니다.
- KarpenterNodeRole-sunghwan-karpenter-demo : Karpenter가 프로비저닝할 노드용
- eksctl-sunghwan-karpenter-demo-nod-NodeInstanceRole-... : 현재 managed node group 노드용
둘 다 system:bootstrappers, system:nodes 그룹으로 정상 매핑되었음을 확인하였습니다.
Karpenter Installation
Helm으로 Karpenter를 설치하기 위해서 아래 명령을 참고해주세요.
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
# Karpenter 설치를 위한 변수 설정 및 확인
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
echo "${CLUSTER_ENDPOINT} ${KARPENTER_IAM_ROLE_ARN}"
# karpenter 설치
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
# 확인
helm list -n kube-system
kubectl get all -n $KARPENTER_NAMESPACE
kubectl get crd | grep karpenter
1) 변수 설정
CLUSTER_ENDPOINT : Karpenter Controller가 EKS API 서버에 직접 통신할 때 필요합니다.
KARPENTER_IAM_ROLE_ARN : CloudFormation 스택이 만들어둔 그 Role이네요. (Pod Identity Association)
2) helm install 옵션 설명
--set "settings.interruptionQueue=${CLUSTER_NAME}"SQS Queue 이름 지정하는 옵션입니다.
CloudFormation 스택이 Queue 이름을 ${CLUSTER_NAME}으로 만들었기 때문에 맞춘 것 입니다.
이게 있어야 Spot Interruption Handling이 활성화돼요.
--set controller.resources.requests.cpu=1
--set controller.resources.limits.cpu=1
--set controller.resources.requests.memory=1Gi
--set controller.resources.limits.memory=1Girequests = limits로 맞춰서 QoS class가 Guaranteed가 됩니다.
Controller 같은 핵심 컴포넌트는 이렇게 설정하는 게 Best Practice입니다.
(OOM이나 CPU throttling으로 Controller가 죽는 상황을 방지하기 때문)
3) 설치가 잘 되었는지 확인

karpenter controller pod가 2개 떠있는 모습을 확인하실 수 있습니다.
(HA를 위해 고정 노드그룹 2개에 파드 1개씩 각각 떠있네요)
추가적으로 CRD가 4개가 떠있는 모습을 확인하실 수 으며, 저희가 다룰 CRD는 실질적으로 2개 입니다.
- EC2NodeClass : AWS 인프라 레이어. AMI, 서브넷, 보안 그룹, IAM Role, 스토리지 등 EC2 수준 설정
- NodePool : Kubernetes 레이어. 인스턴스 타입 제약, taint/label, 리소스 한도, 만료 시간 등
Promethus & Grafana installation
# 프로메테우스 / 그라파나 설치
helm repo add grafana-charts https://grafana.github.io/helm-charts
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create namespace monitoring
# 프로메테우스 설치
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/prometheus-values.yaml | envsubst | tee prometheus-values.yaml
helm install --namespace monitoring prometheus prometheus-community/prometheus --values prometheus-values.yaml
extraScrapeConfigs: |
- job_name: karpenter
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_endpoints_name
- __meta_kubernetes_endpoint_port_name
action: keep
regex: karpenter;http-metrics
# 프로메테우스 얼럿매니저 미사용으로 삭제
kubectl delete sts -n monitoring prometheus-alertmanager
# 프로메테우스 접속
kubectl port-forward --namespace monitoring svc/prometheus-server 9090:80 &
open http://127.0.0.1:9090
# 그라파나 설치
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/grafana-values.yaml | tee grafana-values.yaml
helm install --namespace monitoring grafana grafana-charts/grafana --values grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
version: 1
url: http://prometheus-server:80
access: proxy
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
capacity-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-capacity-dashboard.json
performance-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-performance-dashboard.json
# admin 암호
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
17JUGSjgxK20m4NEnAaG7GzyBjqAMHMFxRnXItLj
# 그라파나 접속
kubectl port-forward --namespace monitoring svc/grafana 3000:80 &
open http://127.0.0.1:3000현재 포트포워딩이 잘 되고 있는지, monitoring 네임스페이스의 파드가 잘 떠있는지 아래와 같이 확인 !

그라파나의 대쉬보드도 확인해볼 수 있습니다 !

04. Create NodePool (Old version: Provisioner CRD)
노드풀을 생성하기 이전에, 흐름도를 보고 어떻게 동작하는지 먼저 살펴보도록 하겠습니다.
Kubernetes ~v0.x 시절에는 provisioner CRD를 썼는데, v1.0 이상부터 NodePool + EC2NodeClass로
완전히 대체되었음을 알립니다.

1) Pending pods + NodePool/EC2NodeClass → Karpenter가 감지
pod가 스케줄링 안 되는 상태(Unschedulable)가 되면 Karpenter가 이를 watch하고 있습니다.
동시에 NodePool/EC2NodeClass도 watch하면서 "어떤 노드를 어떻게 만들 수 있는지" 파악하고 있어요.
2) NodeClaim 자동 생성
Karpenter가 pending pod의 resource request, nodeSelector, affinity, toleration을
분석해서 최적의 인스턴스 타입을 결정하고, 내부적으로 NodeClaim 오브젝트를 만듭니다.
(직접 건드릴 필요 없는 내부 리소스에요)
3) EC2 Fleet API 호출
NodeClaim을 기반으로 EC2 Fleet API를 직접 호출해서 인스턴스를 띄워요.
CA처럼 ASG를 거치지 않아서 속도가 훨씬 빠르겠죠 ?!
4) EC2 인스턴스 → NodeClaim 메타데이터 업데이트
인스턴스가 실제로 떴다는 정보(instance ID, IP 등)가 NodeClaim에 기록됩니다.
5) Node 등록
EC2 인스턴스가 부팅되면서 kubelet이 실행되고, k8s Node 오브젝트로 클러스터에 등록됩니다.
NodeClaim 상태가 Initialized로 바뀌어.
6) Pod 스케줄링
Node가 Ready 상태가 되면 kube-scheduler가 pending pod를 해당 노드에 배치하게 됩니다.
즉, 아까 생성되었던 CRD 4개 중, EC2NodeClass와 NodePool을 저희가 지정을 하여 사용하는 것이고
NodeClaim 등은 Karpenter가 내부적으로 자동 생성하는 것이므로 직접 건드릴 일 없습니다.
이제, NodePool과 EC2NodeClass를 생성해보겠습니다.
# 변수 확인
echo $ALIAS_VERSION
v20260318
# NodePool, EC2NodeClass 생성
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}" # ex) al2023@latest
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass
05. Create a scale up deployment
pause 파드 1개에 CPU 1코어를 할당할 수 있게 실습 디플로이먼트 배포.
# pause 파드 1개에 CPU 1개 최소 보장 할당할 수 있게 디플로이먼트 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF현재 아래와 같이 0개의 파드에서 5개로 스케일 하였는데, 노드가 신규로 생성되었습니다.

노드가 2개 → 3개로 늘어났어요. Karpenter가 새 노드를 프로비저닝을 아래와 같이 동작하였습니다.
ip-192-168-138-45 c5a.2xlarge / $0.3440 / On-Demand / Ready 51s기존 m5.large 2대 외에 c5a.2xlarge 1대가 추가됐어요.
Karpenter가 inflate pod 5개(CPU 1코어씩 = 5코어 필요)를 분석해서 m5.large(2vCPU)로는 부족하다고 판단하고,
c5a.2xlarge(8vCPU)를 선택 한 거에요.
NodePool requirements에서 c/m/r 계열 3세대 이상으로 열어뒀으니 그 중 비용 효율이 맞는 타입을 골랐네요.
여기서 가장 핵심은 CA와 동작을 비교해볼까요?
만약 CA였다면 미리 정의된 노드 그룹의 인스턴스 타입(m5.large)으로만 스케일 업 했을 거에요.
Karpenter는 워크로드를 보고 c5a.2xlarge가 더 적합하다고 스스로 판단 해서 선택한 것입니다.
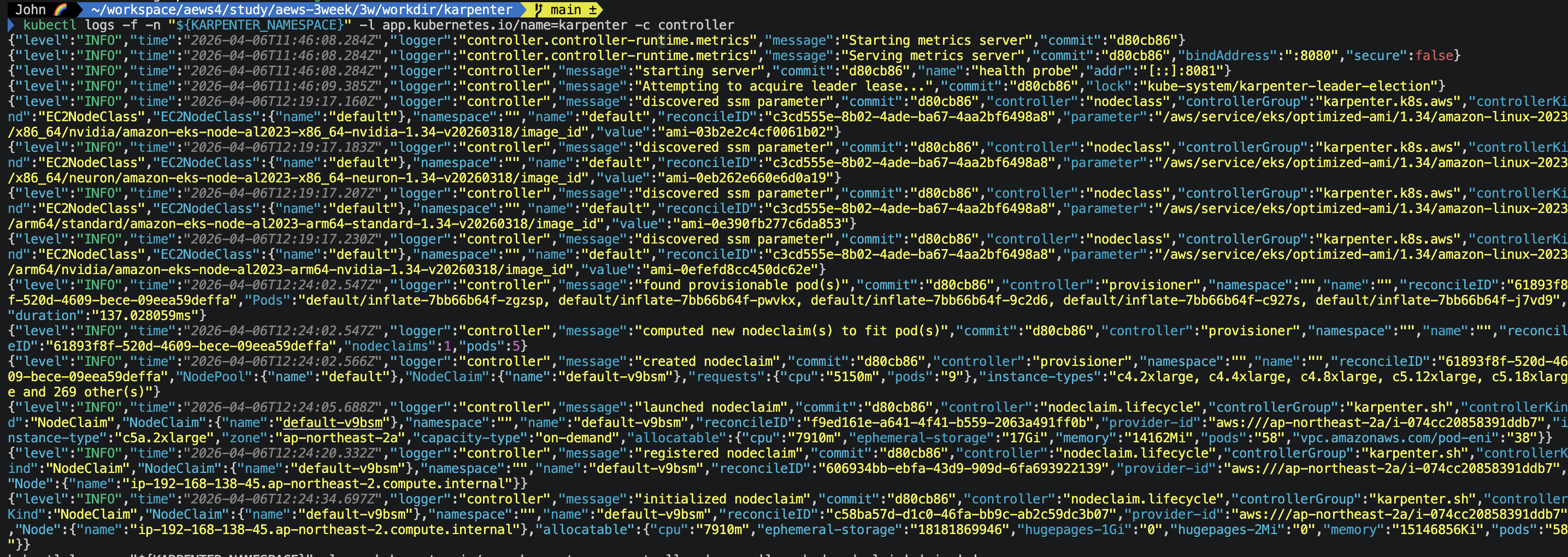
로그가 좀 가시성이 안좋아서 보기 힘든데요, 아래와 같이 확인할 수 있습니다.
1) EC2NodeClass 초기화
discovered ssm parameter ... amazon-linux-2023/x86_64 ... v20260318
discovered ssm parameter ... arm64/standard ... v20260318NodeClass 생성되자마자 SSM Parameter Store에서 AMI ID를 탐색합니다.
x86_64, arm64, nvidia, neuron 변형까지 전부 확인 했네요.
(alias: al2023@v20260318으로 고정했기 때문에 해당 날짜 버전 AMI ID를 가져왔습니다)
2) 프로비저닝 흐름 (타임스탬프 기준)
12:24:02.547 — Pending pod 5개 감지
found provisionable pod(s): inflate x5
duration: 137ms'kubectl scale --replicas 5' 실행 후 pending pod를 137ms 만에 감지. 거의 즉각적이네요
12:24:02.547 — NodeClaim 계산
computed new nodeclaim(s): 1개로 pod 5개 수용 가능5개 pod를 NodeClaim 1개로 처리 가능하다고 판단. 불필요하게 여러 노드 안 만드네요.
12:24:02.566 — NodeClaim 생성
NodeClaim: default-v9bsm
requests: cpu 5150m, pods 9
instance-types: c4.2xlarge, c4.4xlarge, c5.12xlarge ... and 269 other(s)후보 인스턴스가 274개나 됐어요. 그 중에서 비용/사양 최적을 골라서 c5a.2xlarge 선택.
12:24:05.688 — EC2 인스턴스 기동
launched: i-074cc20858391ddb7
instance-type: c5a.2xlarge
zone: ap-northeast-2a
allocatable: cpu 7910m / memory 14162Mi / pods 58NodeClaim 생성 후 3초 만에 EC2 Fleet API 호출 완료.
12:24:20.332 — 클러스터에 Node 등록
registered: ip-192-168-138-45.ap-northeast-2.compute.internalEC2 기동 후 15초 만에 kubelet이 실행되고 Node 오브젝트 등록.
12:24:34.697 — 초기화 완료
initialized nodeclaim
allocatable: cpu 7910m / memory 15146856Ki / pods 58모든 extended resource 등록 완료. pod 스케줄링 시작. EC2 기동부터 Ready까지 총 29초.
Check Nodeclaims
아까 Nodeclaims은 Karpenter가 내부적으로 nodeclaim 오브젝트를 생성한다고 말씀드렸습니다.
확인해볼까요?

현재 2a 영역에 생성되었네요 (ManagedNodeGroup 영역에 침범X)
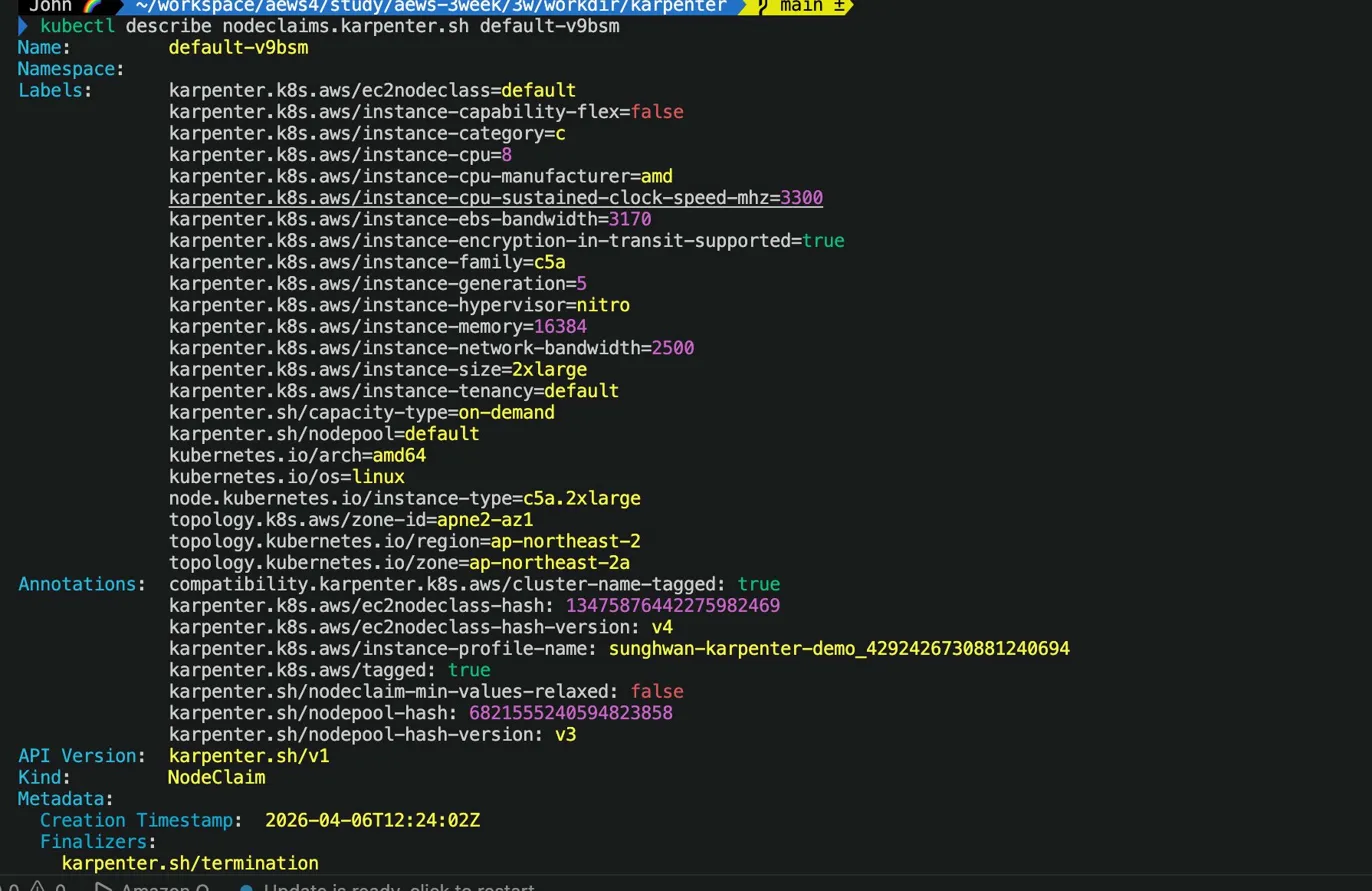
실제로 describe를 찍어보면 많은 내용들이 담겨있습니다.
NodePool requirements에서 필터링할 수 있는 키들이 적혀있네요.
예를 들어 karpenter.k8s.aws/instance-cpu-manufacturer: amd 조건 걸면 Intel 제외하고 AMD만 선택 가능!
그 외에 어노테이션 부분의 hash 값을 보시면 아래와 같이 되어있습니다.
ec2nodeclass-hash: 1347587644275982469
nodepool-hash: 6821555240594823858NodePool이나 EC2NodeClass 설정이 바뀌면 이 해시값이 달라져요.
Karpenter가 이걸 보고 "노드 교체가 필요하다"고 판단합니다.
AMI 버전 업데이트할 때 이 메커니즘으로 롤링 교체가 일어나요.
Shall we keep scaling up?
한번 파드를 계속 스케일 업 해볼게요. 동작 확인을 해봅시다.
kubectl scale deployment inflate --replicas 30아래와 같은 결과가 나왔습니다.

replica 30개(CPU 30코어 필요)를 처리하기 위해 이번엔 c5a.4xlarge 2대를 선택했습니다.
아까 5개일 때는 c5a.2xlarge 1대였는데, 30개가 되니까 더 큰 타입 2대로 분산한 것 입니다.

nodeclaims가 바뀌었습니다. describe 찍어서 아래 로그만 확인해볼까요?

1) Launched (4m16s) : EC2 Fleet API 호출 완료, 인스턴스 기동 시작. 아직 클러스터엔 없는 상태
2) DisruptionBlocked (4m10s) : Launched 직후 6초 만에 Consolidation이 시도됐는데 블록됨.
- "아직 Node 오브젝트가 없으니 건드리지 마" 상태입니다.
- 노드가 완전히 준비되기 전에 Consolidation이 실행되는 걸 방지하는 안전장치에요.
3) Registered (4m1s) : Launched로부터 15초 후, kubelet 실행되고 Node 오브젝트가 클러스터에 등록됨.
4) Initialized (3m50s) : Registered로부터 11초 후. 모든 extended resource 등록 완료, pod 스케줄링 가능 상태.
5) Ready (3m50s) : Initialized와 동시에 Ready. 완전히 사용 가능한 상태.
6) Unconsolidatable (2m34s) : Ready로부터 약 1분 16초 후,
- Consolidation 주기가 돌면서 시뮬레이션 해봤는데 더 저렴한 노드로 교체 불가 판단 → 현재 유지.
06. Scale down deployment
이번에는 pods를 scale down하여 Consolidation 동작까지 확인해볼까요?
scale down 실습은 삭제가 되는 과정 촬영이 어려워, controller 로그로 대체합니다.
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
{
"level": "INFO",
"time": "2026-04-06T11:46:08.284Z",
"logger": "controller.controller-runtime.metrics",
"message": "Starting metrics server",
"commit": "d80cb86"
}
{
"level": "INFO",
"time": "2026-04-06T11:46:08.284Z",
"logger": "controller.controller-runtime.metrics",
"message": "Serving metrics server",
"commit": "d80cb86",
"bindAddress": ":8080",
"secure": false
}
{
"level": "INFO",
"time": "2026-04-06T11:46:08.284Z",
"logger": "controller",
"message": "starting server",
"commit": "d80cb86",
"name": "health probe",
"addr": "[::]:8081"
}
{
"level": "INFO",
"time": "2026-04-06T11:46:09.385Z",
"logger": "controller",
"message": "Attempting to acquire leader lease...",
"commit": "d80cb86",
"lock": "kube-system/karpenter-leader-election"
}
{
"level": "INFO",
"time": "2026-04-06T12:44:40.734Z",
"logger": "controller",
"message": "deleted node",
"commit": "d80cb86",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-138-45.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-138-45.ap-northeast-2.compute.internal",
"reconcileID": "590dd509-8e8f-4d75-997d-798627311e62",
"NodeClaim": {
"name": "default-v9bsm"
}
}
{
"level": "INFO",
"time": "2026-04-06T12:44:41.093Z",
"logger": "controller",
"message": "deleted nodeclaim",
"commit": "d80cb86",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"NodeClaim": {
"name": "default-v9bsm"
},
"namespace": "",
"name": "default-v9bsm",
"reconcileID": "9550fc00-02ec-47bc-a89b-d3a1157fe246",
"provider-id": "aws:///ap-northeast-2a/i-074cc20858391ddb7",
"Node": {
"name": "ip-192-168-138-45.ap-northeast-2.compute.internal"
}
}
{
"level": "INFO",
"time": "2026-04-06T12:55:06.667Z",
"logger": "controller",
"message": "disrupting node(s)",
"commit": "d80cb86",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "b4d5ecf2-1d55-4ff0-a1a8-6d8e006ba188",
"command": "Empty/04772c62-58dd-41f3-a5a1-3dba3cea52df: delete: nodepools=[default]: [ip-192-168-157-163.ap-northeast-2.compute.internal] (savings: $0.69)",
"decision": "delete",
"disrupted-node-count": 1,
"replacement-node-count": 0,
"pod-count": 0,
"disrupted-nodes": [
{
"Node": {
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal"
},
"NodeClaim": {
"name": "default-9lwxc"
},
"capacity-type": "on-demand",
"instance-type": "c5a.4xlarge"
}
],
"replacement-nodes": []
}
{
"level": "INFO",
"time": "2026-04-06T12:55:06.752Z",
"logger": "controller",
"message": "tainted node",
"commit": "d80cb86",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal",
"reconcileID": "97d16af1-3ffe-4e24-90b2-a4bfb70d6107",
"NodeClaim": {
"name": "default-9lwxc"
},
"taint.Key": "karpenter.sh/disrupted",
"taint.Value": "",
"taint.Effect": "NoSchedule"
}
{
"level": "INFO",
"time": "2026-04-06T12:55:31.732Z",
"logger": "controller",
"message": "disrupting node(s)",
"commit": "d80cb86",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "0123c5cb-9651-4016-9b89-6a549432933b",
"command": "Empty/056e104c-f2f7-4e8b-9e91-ed3c978e3383: delete: nodepools=[default]: [ip-192-168-48-251.ap-northeast-2.compute.internal] (savings: $0.69)",
"decision": "delete",
"disrupted-node-count": 1,
"replacement-node-count": 0,
"pod-count": 0,
"disrupted-nodes": [
{
"Node": {
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal"
},
"NodeClaim": {
"name": "default-mvld7"
},
"capacity-type": "on-demand",
"instance-type": "c5a.4xlarge"
}
],
"replacement-nodes": []
}
{
"level": "INFO",
"time": "2026-04-06T12:55:31.827Z",
"logger": "controller",
"message": "tainted node",
"commit": "d80cb86",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal",
"reconcileID": "7454a0a1-ca9a-483a-beea-dcb14807f540",
"NodeClaim": {
"name": "default-mvld7"
},
"taint.Key": "karpenter.sh/disrupted",
"taint.Value": "",
"taint.Effect": "NoSchedule"
}
{
"level": "INFO",
"time": "2026-04-06T12:55:38.509Z",
"logger": "controller",
"message": "deleted node",
"commit": "d80cb86",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal",
"reconcileID": "9b7f4d6c-1700-451a-a499-479191b0ec53",
"NodeClaim": {
"name": "default-9lwxc"
}
}
{
"level": "INFO",
"time": "2026-04-06T12:55:38.732Z",
"logger": "controller",
"message": "deleted nodeclaim",
"commit": "d80cb86",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"NodeClaim": {
"name": "default-9lwxc"
},
"namespace": "",
"name": "default-9lwxc",
"reconcileID": "2eef3bbe-d43d-4ec8-8586-9f0099f74ed2",
"provider-id": "aws:///ap-northeast-2a/i-038b4e499b196afa3",
"Node": {
"name": "ip-192-168-157-163.ap-northeast-2.compute.internal"
}
}
{
"level": "INFO",
"time": "2026-04-06T12:56:03.578Z",
"logger": "controller",
"message": "deleted node",
"commit": "d80cb86",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal",
"reconcileID": "dd6f56a5-a532-4975-b24d-e1834cddc24d",
"NodeClaim": {
"name": "default-mvld7"
}
}
{
"level": "INFO",
"time": "2026-04-06T12:56:03.789Z",
"logger": "controller",
"message": "deleted nodeclaim",
"commit": "d80cb86",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"NodeClaim": {
"name": "default-mvld7"
},
"namespace": "",
"name": "default-mvld7",
"reconcileID": "fab678d3-fd0a-4155-9d62-4d8bb6ce5749",
"provider-id": "aws:///ap-northeast-2a/i-0e5399951a444522d",
"Node": {
"name": "ip-192-168-48-251.ap-northeast-2.compute.internal"
}
}Consolidation 로그를 타임스탬프 기준으로 아래와 같이 정리해보도록 하겠습니다.
첫 번째 삭제 (replicas 5 → 30, 12:44)
12:44:40 deleted node ip-192-168-138-45 (default-v9bsm)
12:44:41 deleted nodeclaim default-v9bsmreplicas 30으로 올릴 때 Karpenter가 c5a.4xlarge를 새로 띄우면서 c5a.2xlarge에 있던
pod들을 재스케줄링해버렸고, 그 시점에 이미 c5a.2xlarge가 빈 노드가 된 거야. 그래서 12:44에 먼저 삭제.
두 번째 삭제 (replicas 30 → 0, 12:55)
c5a.4xlarge 2대를 순차적으로 처리했습니다.
노드 1 (default-9lwxc)
12:55:06 disrupting node(s)
command: "Empty/delete: savings $0.69"
decision: delete / pod-count: 0
12:55:06 tainted node
taint: karpenter.sh/disrupted=NoSchedule
12:55:38 deleted node
12:55:38 deleted nodeclaim노드 2 (default-mvld7)
12:55:31 disrupting node(s) (25초 후 병렬 시작)
command: "Empty/delete: savings $0.69"
12:55:31 tainted node
12:56:03 deleted node
12:56:03 deleted nodeclaim
📌 핵심 포인트
1) Empty 판정 → 즉시 삭제
"pod-count": 0
"replacement-node-count": 0pod가 없으니 대체 노드 없이 바로 삭제. WhenEmptyOrUnderutilized에서 Empty 케이스입니다.
2) Taint 먼저, 삭제 나중
taint: karpenter.sh/disrupted=NoSchedule삭제 전에 반드시 taint를 먼저 달아서 신규 pod 스케줄링을 차단해. 그 다음 drain → delete 순서입니다.
3) 비용 절감 계산까지 로그에 찍힘
savings: $0.69노드 1대당 시간당 $0.69 절감. c5a.4xlarge가 $0.688/hour니까 정확히 일치합니다.
Karpenter가 Consolidation 결정할 때 비용을 실제로 계산해서 판단한다는 게 로그에서 확인돼요.

그라파나 모니터링 도구도 함께 같이 모니터링 해봐도 좋을 것 같습니다~!
실제로 스케일 업, 다운 하면서 변화 추이를 모니터링 해보는 것을 권고드립니다.
긴 글 읽어주셔서 감사합니다.
조금 더 심화된 카펜터 워크숍 실습은 시간이 좀 여유가 생긴다면 포스팅 해보도록 하겠습니다.
(https://catalog.workshops.aws/karpenter/en-US)