Node Scaling using ASG : Cluster Autoscaler
포스팅은 CloudNet@팀 서종호(Gasida)님이 진행하시는
AWS EKS Workshop Study 내용을 참고하여 작성합니다.

안녕하세요!
오늘은 ASG(Auto Scaling Group)을 이용하여
노드 수를 스케일링 해주는 도구인 Cluster Autoscaler를
소개드리고, 학습하는 시간을 갖도록 하겠습니다.

01. CA (Cluster Autoscaler) 개요
CAS는 Kubernetes 클러스터의 노드 수를 자동으로 조정하는 컴포넌트 입니다.
기본 Kubernetes API에 포함된 게 아니라 별도로 배포하는 선택적 구성 요소이고,
Kubernetes 1.8에서 GA(1.0)으로 릴리즈 됐습니다.
AWS에서는 EC2 Auto Scaling Group(ASG)을 백엔드로 사용하며, 클러스터 내에 Deployment 형태로 배포됌.
📌 Scale in / out trigger
CA가 동작하는 조건은 두 가지입니다.
| 조건 | 동작 |
| 리소스 부족으로 Pending 상태인 파드 존재 | worker node scale out |
| 노드가 장시간 저활용 상태이고, 해당 노드의 파드가 다른 노드에 배치 가능 | worker node scale in |
핵심 포인트 : CA는 주기적으로 클러스터 상태를 폴링하는 방식으로 동작합니다.
이벤트 기반이 아닌 인터벌 기반 감지라는 점이 Karpenter와의 중요한 차이점 중 하나입니다.
* Karpenter는 다음 시간에 깊게 배워보도록 하겠습니다.
AWS에서의 동작 구조는 아래와 같습니다.
[Pending Pod 발생]
↓
[CA가 스케줄링 불가 감지 (폴링)]
↓
[어떤 Node Group이 이 파드를 수용할 수 있는지 시뮬레이션]
↓
[해당 ASG의 desired capacity 증가 API 호출]
↓
[EC2 인스턴스 프로비저닝 → 노드 join → 파드 스케줄링]
📌 Scale in 상세 흐름
스케일 인은 스케일 아웃보다 훨씬 보수적으로 동작합니다. (잘못 내리면 파드가 죽어서요)
언더유틸 노드 판단 기준:
노드의 요청된 리소스(Requested) 기준으로 판단합니다. 실제 사용량(Usage)이 아닙니다.
노드의 (sum of pod CPU requests) / (노드 allocatable CPU) < 0.5
AND
노드의 (sum of pod Memory requests) / (노드 allocatable Memory) < 0.5
→ 언더유틸 노드로 마킹이 상태가 --scale-down-unneeded-time (default 10분)동안 지속되면 스케일 인 후보가 됩니다.
스케일 인 안전 검사:
후보 노드가 생겨도 아래 조건이 하나라도 해당되면 스케일 인 하지 않습니다.
- 해당 노드의 파드가 다른 노드에 이동 불가한 경우
- 파드에 PodDistruptionBudget(PDB)이 설정되어 있고 위반되는 경우
- kube-system 네임스페이스의 파드가 있는 경우 (단, DaemonSet 제외)
- 노드에 cluster-autoscaler.kubernetes.io/scale-down-disabled: "true" annotation이 있는 경우
- 로컬 스토리지(emptyDir, hostPath)를 사용하는 파드가 있는 경우
스케일 인 실행:
언더유틸 노드 선정
↓
파드 Drain (--max-graceful-termination-sec 내에 모든 파드 이동)
↓
ASG desired -1
↓
EC2 인스턴스 종료📌 Scale out 상세 흐름
Pending 파드 감지:
CA는 kube-scheduler가 Unschedulable 상태로 표시한 파드를 감지합니다.
정확히는 파드의 condition에서 아래 상태를 확인합니다.
conditions:
- type: PodScheduled
status: "False"
reason: Unschedulable
message: "0/3 nodes are available: 3 Insufficient cpu"
NodeGroup 시뮬레이션:
Pending 파드를 감지하면, CA는 각 Node Group에 노드를 1개 추가했을 때 해당 파드가 스케줄 가능한지
시뮬레이션 합니다. 이때 실제로 노드를 만드는게 아니라 ASG Launch Template 정볼르 바탕으로
가상 노드를 생성해서 scheduler predicates를 돌립니다.
Node Group A (m5.xlarge) 시뮬레이션 → 파드 수용 가능? YES
Node Group B (t3.medium) 시뮬레이션 → 파드 수용 가능? NO (메모리 부족)
↓
Node Group A 선택 → ASG desired +1여러 노드 그룹이 수용 가능하면 expander 정책에 따라 선택합니다.
Expander 정책:
--expander 옵션으로 제어합니다.
| Expander | 동작 |
| random (기본값) | 수용 가능한 Node Group 중 랜덤 선택 |
| least-waste | 스케일 아웃 후 리소스 낭비가 가장 적은 Node Group 선택 |
| most-pods | 한 번에 가장 많은 Pending 파드를 처리할 수 있는 Node Group 선택 |
| priority | 사용자가 우선순위를 직접 지정 (ConfigMap 기반) |
| price | 비용이 가장 낮은 Node Group 선택 (클라우드 provider 지원 필요) |
* 실제 운영에서는 least-waste 또는 priority를 가장 많이 사용한다고 합니다.
📌 ASG 연동 구조
AWS에서 CA가 오토스케일링 그룹을 제어하려면 두 가지 전제조건이 필요합니다.
1) ASG 태그 설정
CA가 어떤 오토스케일링 그룹을 관리 대상으로 볼지 식별하는 태그입니다.
k8s.io/cluster-autoscaler/<클러스터명> = owned
k8s.io/cluster-autoscaler/enabled = trueEKS 관리형 노드 그룹을 사용하면 이 태그가 자동으로 붙습니다.
2) IRSA (IAM Roles for Service Accounts)
CA 파드가 ASG API를 호출할 수 있어야 합니다 (아래는 최소 필요 IAM 권한 입니다)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeScalingActivities",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeImages",
"ec2:DescribeInstanceTypes",
"ec2:DescribeLaunchTemplateVersions",
"eks:DescribeNodegroup"
],
"Resource": "*"
}
]
}SetDesiredCapacity와 TerminateInstanceInAutoScalingGroup이 실제 스케일 동작을 담당합니다.

Cluster Aotuscale 동작을 위해 cluster-autoscaler 파드(디플로이먼트)를 배치한 후,
CA는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃 합니다.
02. CA 배포 전 사전 확인
📌 Auto-Discovery 방식 이해
CA가 어떤 ASG를 관리할지 찾는 방법은 총 4가지 입니다.
| 방식 | 설명 |
| One ASG | 단일 ASG를 --nodes 플래그로 직접 지정 |
| Multiple ASG | 여러 ASG를 --nodes 플래그로 각각 지정 |
| Auto-Discovery | 태그 기반으로 ASG 자동 탐지 (권장) |
| Control-plane Node Setup | 컨트롤 플레인 노드 별도 구성 |
Auto-Discovery가 권장되는 이유:
ASG 이름을 하드코딩할 필요 없이, 태그만 맞으면 자동으로 관리 대상에 포함됩니다.
Node Group을 추가해도 CA 설정을 재배포할 필요가 없습니다.
--node-group-auto-discovery=
asg:tag=k8s.io/cluster-autoscaler/enabled
k8s.io/cluster-autoscaler/<cluster-name>지정한 태그를 모두 가진 ASG만 관리 대상이 되며, --node-group-auto-discovery 플래그로 찾을 태그를 지정.
📌 ASG 태그 확인
위 설명 참고하시면 되며, EKS 관리형 노드 그룹은 생성 시 아래 두 태그가 자동으로 붙습니다.

📌 ASG MaxSize 조정
기본 EKS 관리형 노드 그룹은 Min/Max/Desired가 모두 동일하게 설정되어 있습니다.
CA가 스케일 아웃을 시도해도 MaxSize가 막혀있으면 노드가 추가되지 않습니다.
# 현재 ASG 상태 확인
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
# 출력 예시 (현재 Max가 3으로 잠겨있음)
# +------------------------------------------------+----+----+----+
# | eks-ng1-44c41109-... | 3 | 3 | 3 |
# +------------------------------------------------+----+----+----+MaxSize를 6으로 확장하고 확인해보자.
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" \
--output text)
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 3 \
--desired-capacity 3 \
--max-size 6
# 변경 후 확인
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
# +------------------------------------------------+----+----+----+
# | eks-ng1-... | 3 | 6 | 3 |
# +------------------------------------------------+----+----+----+주의: -nodes 직접 지정 방식과 달리 Auto-Discovery는 ASG의 실제 Min/MAX를 그대로 따릅니다.
CA manifest에서 따로 범위를 지정하지 않기 때문에 ASG의 Max 설정이 곧 스케일 아웃 상한선 입니다.
03. CA Deployment 배포
공식 Auto-Discovery 예제 manifest를 사용합니다.
# manifest 다운로드
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
# 클러스터명 치환
sed -i -e "s|<YOUR CLUSTER NAME>|myeks|g" cluster-autoscaler-autodiscover.yaml
# 배포
kubectl apply -f cluster-autoscaler-autodiscover.yaml아래와 같이 배포를 하면 여러가지 리소스들이 한번에 생성이되네요.

생성된 리소스 목록 및 역할을 말씀드리자면, 아래와 같습니다.
1) serviceaccount/cluster-autoscaler
CA 파드가 사용하는 Kubernetes 서비스 계정입니다.
IRSA와 연결되는 주체이기도 하며, 이 SA에 AWS IAM Role을 어노테이션으로 붙여서
CA가 ASG API를 호출할 수 있게 도와줍니다.
2) clusterrole/cluster-autoscaler
클러스터 전체 범위의 권한 정의입니다. (CA가 클러스터 수준에서 읽고 써야 하는 리소스들에 대한 권한)
nodes — 노드 목록 조회, 어노테이션 수정
pods — Pending 파드 감지, evict 실행
replicationcontrollers, replicasets, statefulsets, daemonsets, deployments — 스케일 인 시 파드 재배치 가능 여부 판단
persistentvolumeclaims — 로컬 스토리지 사용 여부 확인
events — 스케일 이벤트 기록
3) role/cluster-autoscaler
kube-system 네임스페이스 범위의 권한 정의입니다. (ClusterRole과 달리 특정 네임스페이스 내 리소스만 다룸)
configmaps — cluster-autoscaler-status ConfigMap 읽기/쓰기 (현재 상태 기록용)
leases — 리더 선출용 (CAS를 여러 레플리카로 띄울 경우 하나만 활성화되도록)
4) clusterrolebinding/cluster-autoscaler
clusterrole/cluster-autoscaler 권한을 serviceaccount/cluster-autoscaler에 클러스터 범위로 바인딩합니다.
5) rolebinding/cluster-autoscaler
role/cluster-autoscaler 권한을 serviceaccount/cluster-autoscaler에 kube-system 네임스페이스 범위로 바인딩합니다.
6) deployment.apps/cluster-autoscaler
실제 CA가 동작하는 파드를 관리하는 Deployment 입니다.
kube-system 네임스페이스에 배포되고, 위에서 만든 serviceaccount/cluster-autoscaler 를 사용합니다.
즉, 위 항목 전체 구조를 요약하면 아래와 같습니다.
Deployment (cluster-autoscaler 파드 실행)
└─ ServiceAccount (cluster-autoscaler)
├─ ClusterRoleBinding → ClusterRole (클러스터 전체 리소스 접근)
└─ RoleBinding → Role (kube-system ConfigMap/Lease 접근)RBAC 구조가 ClusterRole + Role로 이중으로 분리되는 이유는 최소 권한 원칙 때문입니다.
클러스터 전체를 봐야 하는 권한(노드,파드)과 kube-system 안에서만 필요한 권한(상태 기록용 ConfigMap)을
분리해서 관리합니다.
📌 배포 확인

파드 상태를 확인해보니 running 상태임을 확인할 수 있고, Auto-Discovery 설정 적용도 확인이 되었습니다.
추가로 safe-to-evict 어노테이션이 설정이 되어있어야 합니다. "false"로 되어있는 것 확인
* CA 파드 자신이 스케일 인 대상이 되면 CA가 죽어버리는 아이러니한 상황 방지 설정.
04. Cluster Autoscaling test and monitoring
Step1. IAM Policy 생성 (CA의 Annotation에 IAM Role이 있어야 AWS API호출 가능)
cat << EOF > cas-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeScalingActivities",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeImages",
"ec2:DescribeInstanceTypes",
"ec2:DescribeLaunchTemplateVersions",
"eks:DescribeNodegroup"
],
"Resource": "*"
}
]
}
EOF
aws iam create-policy \
--policy-name CASPolicy \
--policy-document file://cas-policy.json
Step2. IRSA 생성 (eksctl 사용)
eksctl create iamserviceaccount \
--cluster myeks \
--namespace kube-system \
--name cluster-autoscaler \
--attach-policy-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):policy/CASPolicy \
--override-existing-serviceaccounts \
--approve--override-existing-serviceaccounts 플래그가 중요합니다. 이미 SA가 존재하기 때문에 덮어써야 합니다.

CA에 어노테이션이 등록된 것을 확인하였습니다.
Step3. CA 파드 재시작 (아까 CA를 생성하면서 serviceaccount가 생성되었지만 빈껍데기임)
이유는 생성 시에 IRSA가 없었으므로 빈 껍데기의 SA가 생성됐나봐요.
kubectl rollout restart deployment/cluster-autoscaler -n kube-system
# 재시작 후 로그 다시 확인
kubectl -n kube-system logs -f deployment/cluster-autoscalerCA 파드의 러닝 상태를 확인하였습니다.

Step4. 모니터링 먼저 띄워놓고 시작합시다!
# 터미널 1 - 노드 변화 감시
watch -d kubectl get node
# 터미널 2 - EC2 인스턴스 상태 감시
while true; do
aws ec2 describe-instances \
--query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" \
--filters Name=instance-state-name,Values=running \
--output text
echo "------------------------------"
date
sleep 1
done
# 터미널 3 - CAS 로그 실시간 확인
kubectl -n kube-system logs -f deployment/cluster-autoscaler
# 터미널 4 - 작업용위와 같이 설정하게 되면 아래 화면이 나오고, 다른 모니터에 Grafana 등 띄워놓으면 감지하기 쉽습니다!

Step5. nginx deployment 배포(replicas:1)
cat << EOF > nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EOF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
Step6. Max Size를 확인해보자.
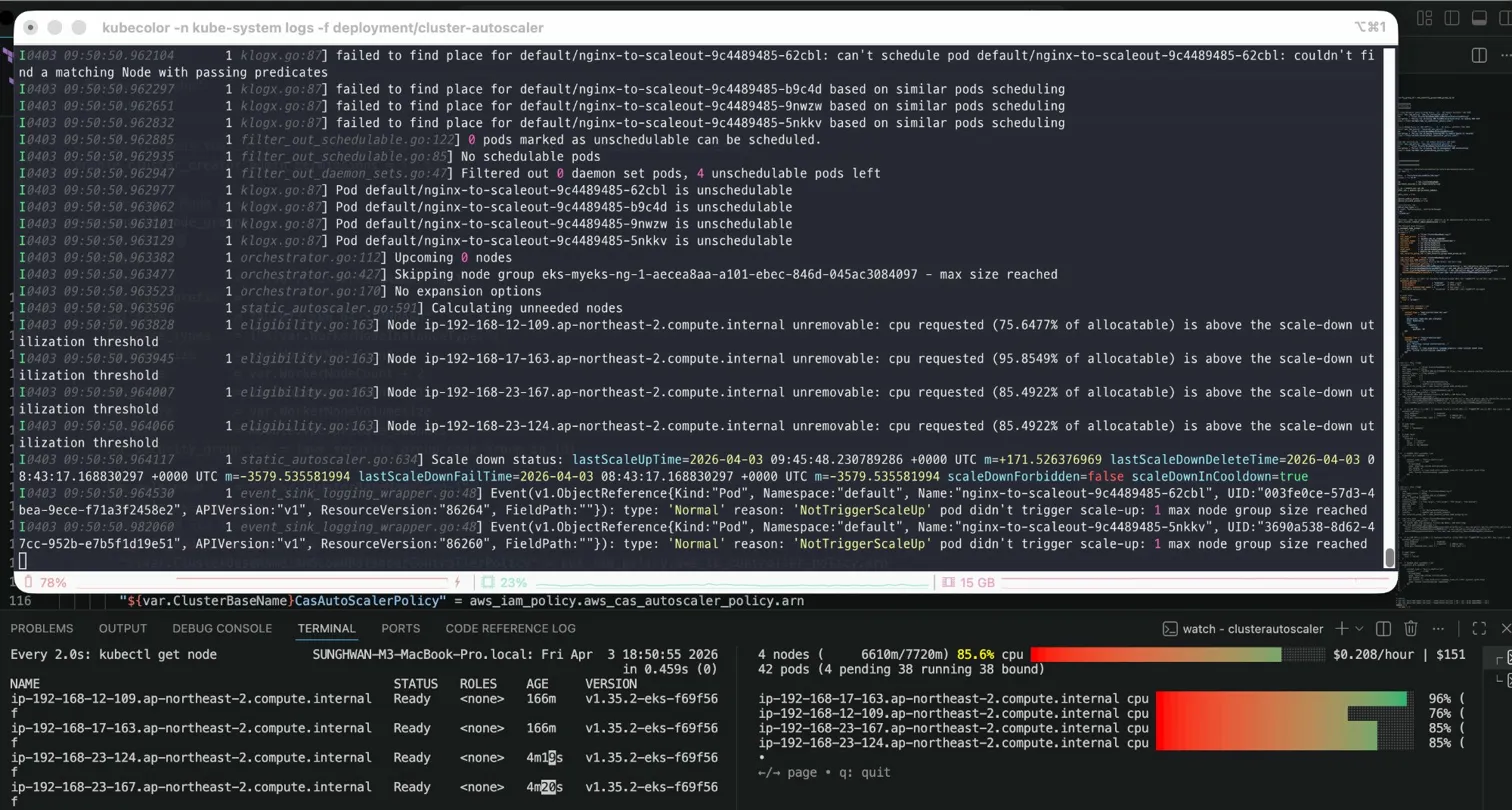
현재 노드 4개 전부다 CPU가 높습니다. 그리고 추가적으로 파드 상태를 볼까요?

아래와 같이 4개의 파드가 Pending 상태에 갇혀있습니다. 그렇다면 Maxsize를 볼까요?

현재 Maxsize가 막혀있으므로, CA가 스케일 아웃을 하지 못하는 상태입니다.
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize, DesiredCapacity]" \
--output table
명령으로 MaxSize를 확인하실 수 있겠습니다.
그렇다면, MaxSize를 올려볼까요?
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 1 \
--desired-capacity 4 \
--max-size 6
Step7. MaxSize를 올렸으니 동작 확인

MaxSize를 6으로 늘렸더니 노드가 늘어난 것을 확인할 수 있습니다.
(CA 로그 중 "No schedulable pods"는 더 이상 Pending 파드가 없으니 스케일 아웃 종료" 멘트입니다)

실제로 kubeopsview로 봤을 때도 pending된 파드가 없이 모두 배치가 잘 되었네요.
Step8. CloudTrail에 CreateFleet 이벤트 확인
아래 링크를 클릭해서 들어가보면 이벤트를 확인하실 수 있습니다.
# ASG desired 변경 시점 (CAS가 호출):
https://ap-northeast-2.console.aws.amazon.com/cloudtrailv2/home?region=ap-northeast-2#/events?EventName=UpdateAutoScalingGroup
# EC2 실제 생성 시점:
https://ap-northeast-2.console.aws.amazon.com/cloudtrailv2/home?region=ap-northeast-2#/events?EventName=CreateFleet
CLI로도 확인하실 수 있습니다.
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=EventName,AttributeValue=SetDesiredCapacity \
--output json | jq '.Events[].CloudTrailEvent | fromjson | {eventTime, userAgent, requestParameters}'
{
"eventTime": "2026-04-03T09:56:22Z",
"userAgent": "aws-sdk-go-v2/1.40.1 ua/2.1 os/linux lang/go#1.25.7 md/GOOS#linux md/GOARCH#amd64 api/autoscaling#1.62.2 cluster-autoscaler/1.35.0 m/E,h",
"requestParameters": {
"autoScalingGroupName": "eks-myeks-ng-1-aecea8aa-a101-ebec-846d-045ac3084097",
"desiredCapacity": 6,
"honorCooldown": false
}
}
{
"eventTime": "2026-04-03T09:45:48Z",
"userAgent": "aws-sdk-go-v2/1.40.1 ua/2.1 os/linux lang/go#1.25.7 md/GOOS#linux md/GOARCH#amd64 api/autoscaling#1.62.2 cluster-autoscaler/1.35.0 m/E,h",
"requestParameters": {
"autoScalingGroupName": "eks-myeks-ng-1-aecea8aa-a101-ebec-846d-045ac3084097",
"desiredCapacity": 4,
"honorCooldown": false
}
}
⚙ John 🍻 ~/workspace/aews4/study/aews-3week/3w/workdir/clusterautoscaler main ±
CA가 desired 4로 올림 (1차 스케일 아웃), desired 6으로 올림 (MaxSize 증가 후 2차 스케일 아웃)
05. Cluster Over-Provisioning - Spare capacity

노드를 수동으로 추가하는 것에 비해 노드는 자동으로 확장하는 것의 단점 중 하나는 아래와 같습니다.
때때로 자동 확장기가 너무 잘 조정되어 여분의 용량이 없을 수 있습니다.
이는 비용을 낮추는 데 도움이 될 수 있지만, 파드를 시작하기 전에 용량을 프로비저닝해야 하므로
새 파드를 시작하는 속도가 느려지겠네요.
새로운 노드를 추가한 후 파드를 시작하는 것은 기존 노드에 새로운 파드를 추가하는 것보다 느립니다.
노드를 프로비저닝하고 부팅해야 하는 반면, 기존 노드로 예약된 파드는 컨테이너를 당겨 부팅하기만 하면 됩니다.
컨테이너가 이미 캐시에 있는 경우 바로 부팅을 시작할 수도 있습니다.
그림 6.2에 표시된 바와 같이, 새로 예약된 Pod는 부팅을 시작하기 전에 용량이 프로비저닝될 때까지 기다려야 합니다.
오토스케일러를 유지하면서 이 두 가지 문제를 해결하는 한 가지 방법은
우선순위가 낮은 플레이스홀더 포드를 사용하는 것입니다.
Cluster Over-Provisioning이 왜 필요할까? CA의 근본적인 한계를 봐봅시다.
일반 CA 동작:
Pending 파드 발생 → CAS 감지 (10초) → ASG API 호출 → EC2 프로비저닝 (~2분) → 노드 join → 파드 스케줄링
↑
이 구간이 문제EC2 프로비전이 + 노드 조인까지 보통 2~5분이 걸립니다.
그동안 파드는 Pending 상태로 대기하며, 트래픽 스파이크가 왔을 때 2~5분은 치명적입니다.
그래서 Placeholder Pod 기술이 필요한데요, 아키텍처는 아래와 같습니다.

[정상 상태]
노드 1: [실제 워크로드] [실제 워크로드] [placeholder] [placeholder]
노드 2: [실제 워크로드] [placeholder] [placeholder] [placeholder]
노드 3: [placeholder] [placeholder] [placeholder] [placeholder] ← 여분 노드placeholder 파드가 여분 노드를 살아있게 유지합니다.
아무 일도 안 하지만 리소스를 점유하고 있어서 CA가 "이 노드는 필요하다"고 판단해 종료하지 않습니다.
📌 트래픽 스파이크 발생 시
[스파이크 발생]
실제 워크로드 파드 증가
↓
우선순위 높은 파드(기본값 0)가 우선순위 낮은 placeholder(-10)를 선점(Preempt)
↓
placeholder 파드 즉시 종료 (terminationGracePeriodSeconds: 0)
↓
실제 워크로드가 빈 자리에 즉시 스케줄링 ← 2~5분 대기 없음!
↓
placeholder 파드가 Pending 상태로 전락
↓
CA가 Pending 감지 → 새 노드 프로비저닝 (백그라운드에서 조용히)
↓
새 노드 뜨면 placeholder 다시 배치 → 여분 용량 복구
📌 PriorityClass 동작 원리
placeholder pod deployment를 만드려면 먼저 PriorityClass가 필요합니다.
placeholder-priority: value -10, preemptionPolicy: Never
↓
일반 파드 (기본 우선순위 0, PreemptLowerPriority)
↓
일반 파드 > placeholder → 일반 파드가 자리 필요하면 placeholder 강제 퇴출preemptionPolicy: Never가 placeholder에 설정된 이유:
placeholder 자신은 다른 파드를 절대 밀어내지 않겠다는 의미입니다.
자기보다 낮은 우선순위가 없으니 의미없지만 명시적으로 선언하는 거예요.
그래서 PriorityClass 예시 yaml파일을 보면 0보다 낮은 순위를 가져야 합니다.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: placeholder-priority
value: -10
preemptionPolicy: Never
globalDefault: false
description: "Placeholder Pod priority."
PriorityClass & Placeholder pod 생성
Step1. PriorityClass 생성
cat << EOF | kubectl apply -f -
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: placeholder-priority
value: -10
preemptionPolicy: Never
globalDefault: false
description: "Placeholder Pod priority."
EOFvalue: 숫자가 높을수록 우선순위 높음. 기본 파드가 0이니까 -10은 항상 밀려남
preemptionPolicy:
- PreemptLowerPriority — 자신보다 낮은 우선순위 파드를 밀어낼 수 있음
- Never — 절대 다른 파드 밀어내지 않음. placeholder는 스스로 공간 뺏으면 안 되니까 Never
Step2. Placeholder Deployment 생성
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: placeholder
spec:
replicas: 10
selector:
matchLabels:
pod: placeholder-pod
template:
metadata:
labels:
pod: placeholder-pod
spec:
priorityClassName: placeholder-priority
terminationGracePeriodSeconds: 0
containers:
- name: ubuntu
image: ubuntu
command: ["sleep"]
args: ["infinity"]
resources:
requests:
cpu: 200m
memory: 250Mi
EOFterminationGracePeriodSeconds: 0 이게 핵심이에요.
선점당할 때 graceful shutdown 없이 즉시 죽어야 실제 워크로드가 바로 그 자리를 차지할 수 있습니다.
1초라도 기다리면 그만큼 지연이 생겨요.
requests 크기는 실제 워크로드 파드보다 작으면 안 됩니다.
placeholder가 밀려난 자리에 실제 워크로드가 들어와야 하는데, 자리가 더 작으면 못 들어가요.

현재 placeholder 파드가 10개 모두 러닝 상태로 배치가 되어 있습니다.

현재 nginx app 파드가 15개 모두 러닝 상태로 되어있는데, 30개로 늘려보도록 하겠습니다.
Step3. nginx 파드 스케일 아웃
kubectl scale --replicas=30 deployment/nginx-to-scaleout && dateplaceholder 선점 트리거 확인을 하기 위해 30개로 스케일 아웃 해보겠습니다.

현재 nginx 파드들이 pending 상태에서 노드 뜨길 기다리지 않고 즉시 스케줄링 되었습니다.
왼쪽 하단 터미널이 placeholder인데, nginx app 파드에 자리를 내어주고 밀려났네요.

Step4. CA가 동작하면서 노드가 스케일 아웃된다면?
(참고로 MaxSize를 올려야 하며 15으로 올리겠습니다.)

노드가 총 11대가 배치되면서 nginx app 파드가 정상적으로 다 올라왔네요.
아래와 같이 Over-Provisioning의 동작 과정을 살펴볼 수 있겠습니다.
새 노드 5개 추가됨 (6 → 11개)
↓
새 노드에 여유 공간 생김
↓
Pending이었던 placeholder들이 새 노드에 다시 배치됨
↓
다시 여분 용량 확보 완료
긴 글 읽어주셔서 감사합니다.
다음 글은 Karpenter를 올려서 직접 테스트를 해보고, CA와 비교를 해볼 예정입니다.
이 글을 참고해주셔도 좋습니다!