Introducing the Cluster Proportional Autoscaler
포스팅은 CloudNet@팀 서종호(Gasida)님이 진행하시는
AWS EKS Workshop Study 내용을 참고하여 작성합니다.

안녕하세요!
오늘은 CPA 기술에 대해서 학습해보고
도전과제인 terraform으로 함께 배포까지 해보도록 하겠습니다.

01. CPA (Cluster Proportional Autoscaler)
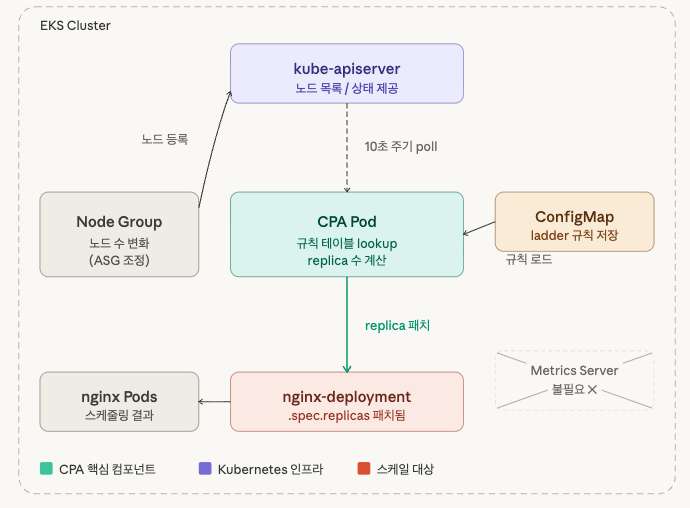
CPA는 클러스터 노드 수(또는 CPU core 수)에 비례해서 특정 Deployment/ReplicaSet의 replica를
자동으로 조정하는 컨트롤러 입니다.
📌 핵심 포인트:
- HPA는 Pod의 CPU/Memory 사용량을 보고 스케일 하는 반면, CPA는 노드 수 자체를 보고 스케일.
- Metrics Server가 불필요 합니다. 오직 kube-apiserver에서 노드 목록만 조회하면 됩니다.
- 주 사용처 : CoreDNS, kube-proxy 등 노드 수에 비례해서 늘려야 하는 인프라성 컴포넌트
[노드 수 변화] ──→ [CPA가 kube-apiserver 폴링] ──→ [규칙 lookup] ──→ [Deployment replica 패치]
"Metrics Server가 왜 불필요할까?"
HPA를 사용해봤다면 이런 경험이 있을거에요.
'kubectl top pods'가 안되면 HPA도 동작 안함.
Metrics Server가 죽으면 HPA가 scaling 판단을 못함 → 트래픽 폭증해도 replica 그대로.
Metrics Server 자체가 모든 노드의 kubelet을 polling해야 하기 때문에 클러스터 규모가 커질수록
메트릭 서버 자체가 병목이 됩니다.
CPA는 이 의존성 체인을 통째로 건너뛰어서 내부적으로 하는 일은 아래와 같습니다.
GET /api/v1/nodes → items[].status.conditions[Ready=True] 카운트kube-apiserver에 노드 목록 달라는 API 한 번이 전부입니다.
이건 모든 kubernetes cluster에 항상 살아있는 api고, 노드가 Ready 상태인지 확인하는건 etcd에서 바로 나오는 정보입니다.
추가 컴포넌트 설치, 추가 장애 포인트, 추가 비용이 전혀 없습니다.
두 가지 스케일링 모드
📌 ladder 모드 (계단식)
노드 수 → replica 수를 명시적 테이블로 지정합니다.
config:
ladder:
nodesToReplicas:
- [1, 1] # 노드 1개 → replica 1
- [2, 2] # 노드 2개 → replica 2
- [3, 3]
- [4, 3] # 노드 4개여도 replica 3 (의도적 절약)
- [5, 5]노드 수가 테이블 사이 값이면 내림(floor)적용합니다.
ex: 노드 3개면 [3,3] 적용
[ coresToReplicas도 같은 구조로 CPU 코어 합계 기준으로 지정도 가능합니다. ]

ladder 테이블의 [4, 3] 케이스가 왜 있는가?
이게 처음 보면 버그인 것 같지만, 의도적인 설계입니다. 노드 4개일 때 replica를 3으로 유지하는 이유는
노드 3→4→5 사이에서 불필요한 replica 생성을 막기 위한 경우
- 노드가 4개일 때 replica를 4개 만들어야 할 이유가 없는 경우
- (예: CoreDNS는 노드 4개 정도면 3개로도 충분히 커버)
노드 수가 왔다갔다할 때 replica가 과하게 튀는 걸 방지하는 dampening(댐핑) 효과.
📌 linear 모드 (비례식)
수식: replicas = max(ceil(cores/coresPerReplica), ceil(nodes/nodesPerReplica))linear 모드는 수식이 중요해서, 수식을 기준으로 설명드리도록 하겠습니다.

위 숫자를 그대로 수식에 대입해서 설명드리도록 하겠습니다.
1) 수식 값 대입
config:
linear:
nodesPerReplica: 1
coresPerReplica: 2
min: 1
max: 10클러스터 상태 : 노드 2개, 노드당 2 vCPU를 가지고 있습니다.
2) 수식 전개
replicas = max(
ceil(노드 수 ÷ nodesPerReplica),
ceil(전체 코어 ÷ coresPerReplica)
)
→ min/max로 클램핑
3) 숫자 대입:
전체 코어 = 2 × 2 = 4
replicas = max(
ceil(2 ÷ 1), → ceil(2.0) = 2
ceil(4 ÷ 2) → ceil(2.0) = 2
)
= max(2, 2) = 2
→ min(1) / max(10) 클램핑: 2는 범위 안 → 최종 replica = 2
" 두 경로를 max로 취한다"는 게 왜 중요한가?
위젯 사진에서 노드당 코어를 2에서 8로 올렸을 때를 가정해보자. 그렇다면 아래의 결과가 나옵니다.

그렇다면 아래의 수식 결과가 나옵니다.
전체 코어 = 2 × 8 = 16
replicas = max(
ceil(2 ÷ 1), → 2 ← 노드 수 그대로, 변화 없음
ceil(16 ÷ 2) → 8 ← 코어가 늘었으니 급증
)
= max(2, 8) = 8
→ max(10) 안 걸림 → 최종 = 8노드 수는 그대로인데 replica가 2에서 8로 급증합니다.
고성능 인스턴스로 마이그레이션했을 때 ladder 모드였으면 테이블을 손으로 다시 짜야 하는 상황을
linear는 자동으로 커버하고 있는 상황입니다.
뭔가 수식 기준으로 설명드려서 와닿지 않을 수도 있습니다.
실제 EKS 운영 시나리오로 풀어드리겠습니다.
시나리오1. 평상시 (스크린샷 세팅 그대로 진행합니다)
클러스터 스펙 : 노드 2개, 노드 당 2 vCPU, nodesPerReplica=1, coresPerReplica=2
그럼 결과는 replica = 2겠죠 ?
즉, CoreDNS가 2개 떠있습니다. (노드 2개니까 각 노드에 1개씩 분산돼서 한 노드가 죽어도 DNS는 살아있음)
시나리오2. 트래픽 대응으로 노드를 갑자기 10개로 늘렸을 때
nodesPerReplica=1 이니까
ceil(10 ÷ 1) = 10
ceil(20 ÷ 2) = 10
→ replica = 10CPA가 아무도 안 건드렸는데 CoreDNS를 2에서 10으로 자동 증가 시킵니다.
노드 10개에 Pod 수백 개가 갑자기 뜨는 상황에서 DNS 요청이 폭증해도 버틸 수 있습니다.
이걸 HPA로 하려면 CoreDNS CPU가 이미 터지고 나서야 반응하는데, CPA는 노드 추가 시점에 선제적으로 올림.
시나리오3. c5.large(2코어)에서 c5.4xlarge(16코어)로 인스턴스 타입을 바꿨을 때
노드 수는 그대로 2개인데 코어가 달라집니다.
전체 코어 = 2 × 16 = 32
ceil(2 ÷ 1) = 2 ← nodes 경로, 변화 없음
ceil(32 ÷ 2) = 16 ← cores 경로, 급증
→ replica = 16 (max(10)에 걸려서 실제론 10)ladder 모드였으면 [2,2] 테이블 그대로라서 replica가 2개에 머무릅니다.
인스턴스 업그레이드 했는데 DNS는 그대로 2개인 상황이네요.
그럼 결국 고성능 노드 위에서 돌아가는 수백 개 Pod가 DNS 2개한테 몰리는 상황이 생기는데
반면, linear는 인스턴스 타입 변경을 자동으로 감지해서 대응해줍니다.
한줄 요약
- nodesPerReplica는 "클러스터 규모"를 봅니다.
- coresPerReplica는 "실제 컴퓨팅 파워"를 봅니다.
둘 중 더 위험한 쪽을 자동으로 채택하는 게 max() 의 역할이구요.
HPA vs VPA vs CPA 한줄 비교 분석
| 항목 | HPA | VPA | CPA |
| 스케일 기준 | Pod 리소스 사용량 | Pod 리소스 사용량 | 노드 수 / CPU 코어 수 |
| 조정 대상 | replica 수 | requests/limits | replica 수 |
| Metrics Server 필요 | ✅ | ✅ | ❌ |
| 주 사용처 | 앱 워크로드 | 리소스 우측화 | 인프라 컴포넌트 |
02. 실습 로드맵
이번 실습에서는 ladder 모드 기반으로 진행할 예정입니다.
이유1. CPA 자체가 쓰이는 상황이 한정적
CPA의 주 타깃은 CoreDNS입니다. 그 외엔 kube-proxy, metrics-server 같은 인프라 컴포넌트 정도구요.
실제로 Kubernetes 공식 문서에서도 CoreDNS 스케일링 예시로 CPA를 소개해.
근데 CoreDNS 스케일링 목적이면 ladder로 충분합니다.
"노드 10개까지는 2개, 20개까지는 3개" 이런 식으로 명시적으로 관리하는 게 운영자 입장에서 오히려 예측 가능하고 편하겠죠.
이유2. linear의 장점인 "인스턴스 타입 변경 자동 대응"이 실제로 잘 안쓰임
EKS에서 인스턴스 타입을 바꾸는건 노드 그룹 교체라 어차피 작업이 크게 들어갑니다.
그 김에 CPA 규칙도 같이 손을 보는 것이지, linear 동작 하나만으로 통제가 어렵습니다.
coresPerReplica값을 얼마노 설정하는지 자체가 감으로 잡기 어려워서 오히려 ladder보다 튜닝이 힘들겠네요.
이러한 이유로 인해서 실습은 ladder 모드로 진행할 예정입니다 ~
📌 ladder 모드 실습
1) Helm 레포 추가
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
2) 실습 nginx deployment 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml
3) CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
4) Helm 차트 릴리즈
helm upgrade --install cluster-proportional-autoscaler \
-f cpa-values.yaml \
cluster-proportional-autoscaler/cluster-proportional-autoscaler
5) 규칙 적용 확인

이제 한번 노드를 5개로 증가시키고, 축소해보는 실습을 해보도록 하겠습니다.
# 노드 5개로 증가
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table노드를 5개일때 replica를 5개로 지정하였고, 실제로 늘어난 것을 아래와 같이 확인이 가능합니다.

# 노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
노드를 4개로 줄이니 규칙에 따라 replica가 3으로 변경되었습니다.
먼저 파드가 3개로 줄어들고, 30초 내로 노드 하나가 줄어드는 것까지 확인하였습니다.
03. EKS addon 중 coredns 를 테라폼 배포 시, autoscaling 정책을 적용
EKS CoreDNS addon에 CPA autoscaling 정책을 넣어보도록 하겠습니다.
저번에 external dns addon에 "policy=sync" 넣었던 것 처럼 같은 맥락으로 넣으면 될 것 같습니다.
📌 CoreDNS addon을 Terraform 코드에 추가하여 배포
# 기존 coredns addon 셋팅
addons = {
coredns = {
most_recent = true
}
# 변경될 coredns addon 셋팅
addons = {
coredns = {
most_recent = true
configuration_values = jsonencode({
autoScaling = {
enabled = true
minReplicas = 2
maxReplicas = 10
}
})
}apply 이전에 'terraform plan'으로 확인하여 변경될 사항을 미리 확인하는 습관 !

아, 방금은 EKS가 자체적으로 CoreDNS replica를 관리하겠다고 선언한 내용이였고,
아래와 같이 CPA Pod가 직접 kube-apiserver를 polling해서 노드 수를 확인하고 ladder 테이블대로
CoreDNS를 패치한다는 규칙을 명시해준 것입니다.
provider "helm" {
kubernetes = {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec = {
api_version = "client.authentication.k8s.io/v1beta1"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
command = "aws"
}
}
}
resource "helm_release" "cpa_coredns" {
name = "cpa-coredns"
repository = "https://kubernetes-sigs.github.io/cluster-proportional-autoscaler"
chart = "cluster-proportional-autoscaler"
namespace = "kube-system"
values = [jsonencode({
config = {
ladder = {
nodesToReplicas = [
[1, 2],
[5, 3],
[10, 5],
[20, 7]
]
}
}
options = {
namespace = "kube-system"
target = "deployment/coredns"
}
})]
depends_on = [module.eks]
}
eks.tf 파일의 맨 마지막에 위 규칙을 추가한 후에 다시 terraform plan, apply 합시다 !

📌 애드온으로 스케줄링이 되는지 테스팅
먼저, 아래와 같이 terraform에서 추가한 CPA Helm release 입니다.

- --target=deployment/coredns : CPA가 감시하고 패치할 대상이 여기에 명시됩니다.
- --configmap=cpa-coredns-cluster-protortional-autoscaler
- ladder 규칙이 저장된 configmap 이름이네요. CPA가 여기서 nodeToReplicas 테이블을 읽음.
- --namespace=kube-system : CoreDNS가 있는 네임 스페이스입니다.
- --v=0 : 로그 verbosity가 0입니다 즉, 최소한의 로그만 출력하겠단 의미겠죠.
이제 노드를 5개로 늘려보겠습니다.
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" \
--output text)
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 5 --desired-capacity 5 --max-size 5
CPA 규칙을 명시하였던 대로 노드 5개가 올라오니, replica 수는 3개가 되었습니다.
이제, 노드 수를 10개로 올려볼까요?

네 10개로 올렸더니 coreDNS의 replica 수가 5개로 증가한 것을 확인할 수 있습니다.
이렇게 terraform으로 애드온 + CPA 규칙을 같이 배포하면 장점이 뭘까?
- 클러스터를 재생성해도 자동으로 붙습니다 (helm upgrade --install 안해도됌)
- CPA 규칙이 git에 남아서 "언제 누가 노드 기준을 바꿨는지" PR로 추적 가능.
- 또한 팀원이 ConfigMap을 직접 수정하는 사고도 방지를 할 수 있겠죠
- depends_on으로 순서를 보장해줍니다.
- CoreDNS가 완전히 뜨기 전에 CPA가 먼저 붙으려다 실패하는 타이밍 문제 해결.
긴 글 읽어주셔서 감사합니다.
다음 주제는 Cluster AutoScaler 기술로 찾아뵙도록 하겠습니다.