Introduction to Additional EKS Add-ons
포스팅은 CloudNet@팀 서종호(Gasida)님이 진행하시는
AWS EKS Workshop Study 내용을 참고하여 작성합니다.

안녕하세요!
3주차에 들어오면서 변경된 테라폼 코드와
추가된 Add-on (external DNS, metrics-server)에 대해서
소개해보도록 하겠습니다.

01. 실습 환경 배포 Terraform 코드 변경점
이번 실습에서는 노드를 Private Subnet으로 배치하면서 SSH 접속 환경이 없어졌는데요,
Terraform eks.tf 코드 중 크게 3가지 축으로 아래와 같이 확장되었습니다.
1) Logs 설정
kubernetes_version = var.KubernetesVersion # 1.35
enabled_log_types = ["api", "scheduler"]Control Plane 로그를 CloudWatch로 보내는 설정이 추가되었습니다.
api는 kube-apiserver 로그, scheduler는 스케줄링 결정 로그. 이전엔 없던 부분이네요.
2) 노드 설정 변경
subnet_ids = module.vpc.private_subnets # 노드를 private에 배치
AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"노드가 private subnet에 있으면 SSH 직접 접근이 안 되니까,
SSM Session Manager로 접속할 수 있게 IAM 정책을 인스턴스 프로파일에 붙인 것 입니다.
3) IAM Policy + Add-on 추가
- aws_lb_controller_policy.json
curl -o aws_lb_controller_policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/refs/heads/main/docs/install/iam_policy.jsonAWS Load Balancer Controller가 ALB/NLB를 직접 생성/수정/삭제할 수 있게 허용하는 정책이에요.
elasticloadbalancing:* , ec2:Describe* , cognito-idp:* 등 수십 개 권한이 들어있습니다.
GitHub에서 공식 제공하는 파일을 그대로 가져다 쓰는 거고, IRSA로 LBC 서비스 어카운트에 연결하게 됩니다.
- externaldns_controller_policy.json
cat << EOF > externaldns_controller_policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"route53:ChangeResourceRecordSets",
"route53:ListResourceRecordSets",
"route53:ListTagsForResources"
],
"Resource": [
"arn:aws:route53:::hostedzone/*"
]
},
{
"Effect": "Allow",
"Action": [
"route53:ListHostedZones"
],
"Resource": [
"*"
]
}
]
}
EOFExternalDNS가 Route 53 레코드를 자동 관리할 수 있게 허용합니다.
route53:ChangeResourceRecordSets — 실제 DNS 레코드 생성/수정/삭제
route53:ListHostedZones / ListResourceRecordSets — 존재하는 레코드 조회
ListTagsForResources — 태그 기반 필터링
- cas_autoscaling_policy.json
cat << EOF > cas_autoscaling_policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeScalingActivities",
"ec2:DescribeImages",
"ec2:DescribeInstanceTypes",
"ec2:DescribeLaunchTemplateVersions",
"ec2:GetInstanceTypesFromInstanceRequirements",
"eks:DescribeNodegroup"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
],
"Resource": ["*"]
}
]
}
EOFCluster Autoscaler(CAS)가 노드 수를 자동으로 늘리고 줄일 수 있게 허용합니다.
Describe* 계열 — 현재 ASG 상태/인스턴스 타입 조회 (읽기)
SetDesiredCapacity — 노드 수 증가 (스케일 아웃)
TerminateInstanceInAutoScalingGroup — 노드 제거 (스케일 인)
이 세 정책을 노드 IAM 역할(Instance Profile)에 직접 붙여서 사용하고 있는데요,
iam_role_additional_policies = {
"...LoadBalancerControllerPolicy" = aws_iam_policy.aws_lb_controller_policy.arn
"...ExternalDNSPolicy" = aws_iam_policy.external_dns_policy.arn
"...CasAutoScalerPolicy" = aws_iam_policy.aws_cas_autoscaler_policy.arn
AmazonSSMManagedInstanceCore = "..."
}원래 IRSA(Service account에 IAM Role 연결)가 정석이지만, 실습 편의상 인스턴스 프로파일에
직접 붙여서 사용하도록 구성이 되어있습니다.
이렇게 되면 파드의 최소 권한 부여 원칙에 위배가 되는 사항이긴 해서 실제 프로덕션 환경에선 절대 권장하지 않습니다.
(실무에선 무조건 최소 권한 원칙 상 IRSA 권장함)
추가된 Add-on
- metrics-server : kubectl top nodes/pods 명령어와 HPA(Horizontal Pod Autoscaler)가 동작하려면 반드시 필요한 리소스 메트릭 수집기예요.
- external-dns : Ingress나 Service에 external-dns 어노테이션을 붙이면, Route 53 레코드를 자동으로 생성/삭제해줘요. ALB Ingress와 함께 쓰면 도메인 설정이 자동화돼요.
02. 추가된 EKS Add-on 확인
metrics-server 상세 정보 확인
kubectl get deploy -n kube-system metrics-server
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 2/2 2 2 33mreplica가 2개로 띄워져 있습니다. (직접 설치하면 1개)
EKS 관리형 애드온으로 설치하면 HA 구성(2개)으로 띄워줘요.
system-cluster-critical PriorityClass가 붙어있어서 리소스 부족 시 일반 파드보다 먼저 보호됩니다.
Args: 섹션 확인
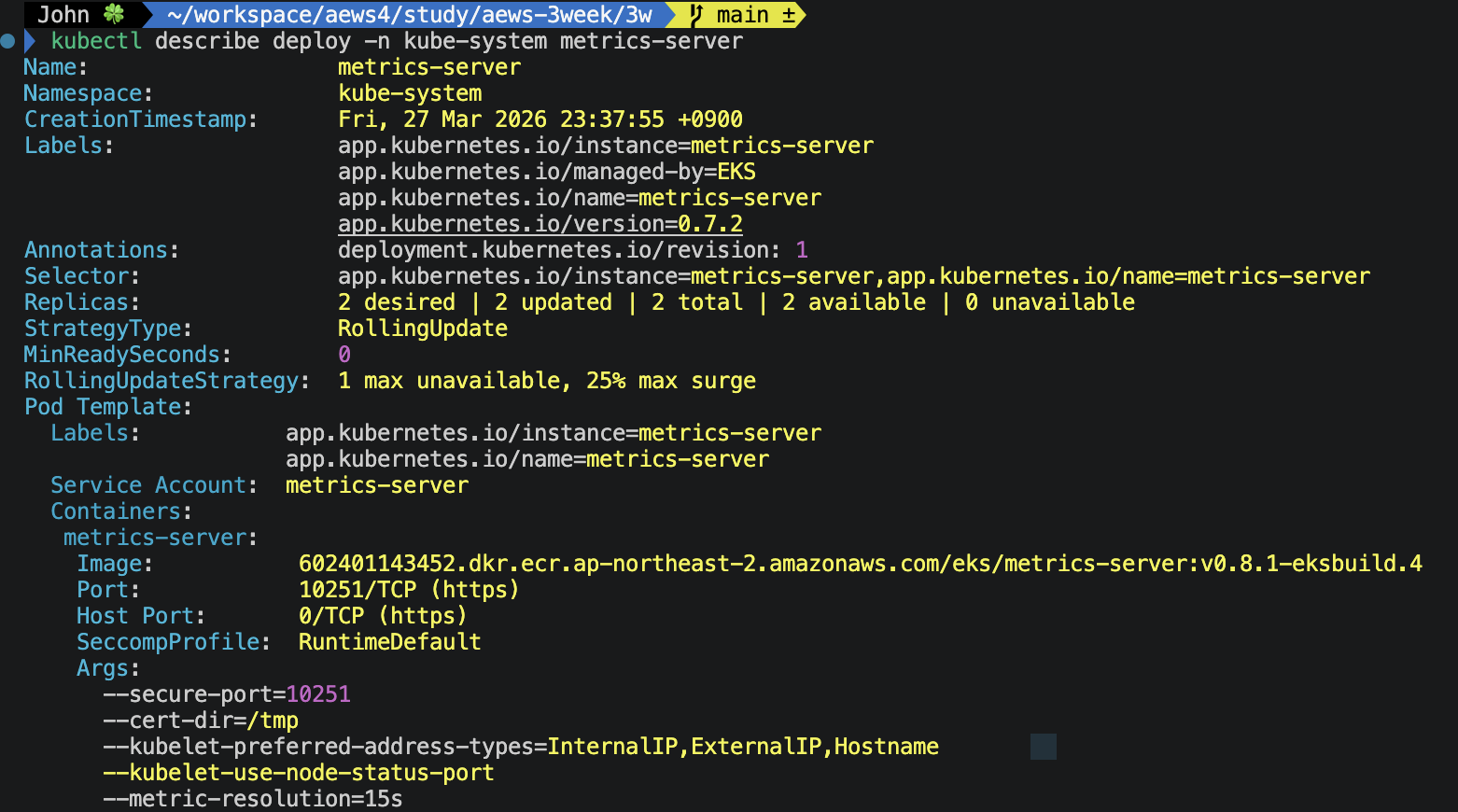
--secure-port=10251 : HTTPS로만 통신. (HTTP 포트가 없습니다.)
--kubelet-preferred-address-types=InternalIP : kubelet에 접근할 때 Internal IP 우선
(Private subnet 환경이라 당연한 설정)
--kubelet-use-node-status-port : kubelet의 메트릭 수집 포트를 Node 상태에서 동적으로 읽어옴
--metric-resolution=15s : 15초마다 메트릭 수집

리소스 제한 보시면 CPU에 대한 limits이 없습니다.
메모리만 400Mi로 cap. 클러스터 노드 수가 많아지면 메트릭 수집 부하가 커지므로,
CPU를 제한하면 스크레이핑이 밀릴 수 있어서 의도적으로 열어둔 것 같네요.
Topology Spread Constraints
2개 파드가 서로 다른 AZ에 분산 배치되도록 유도합니다.
ScheduleAnyway 라서 AZ가 하나밖에 없어도 강제 실패하지는 않고, 가능하면 분산하는 소프트 제약이에요.
실제로 보면 AZ가 다른 노드에 각각 올라가 있어요. 의도대로 분산된 겁니다.

PDB (PodDisruptionBudget)

노드 drain 같은 자발적 중단(voluntary disruption) 상황에서 최대 1개까지만 동시에 내려갈 수 있습니다.
replica가 2개니까, 항상 최소 1개는 살아있음을 보장하네요.
Service & Endpoints

ClusterIP:443 으로 들어오면 실제 파드의 10251 포트로 라우팅 됩니다.
(Service의 targetPort가 10251로 매핑)
metrics-server api 관련 정보 확인
📌 metrics-server가 Kubernetes API에 붙는 방식

v1beta1.metrics.k8s.io → kube-system/metrics-server → AVAILABLE: Truemetrics-server는 단순한 파드가 아닙니다. API Aggregation 방식으로 kube-apiserver에 자신을 등록해요.
kubectl top nodes
↓
kube-apiserver (metrics.k8s.io/v1beta1 요청 수신)
↓
metrics-server 파드로 프록시
↓
각 노드 kubelet에서 메트릭 수집 후 응답kubectl explain NodeMetrics가 동작하는 이유가 바로 이 것입니다.
metrics-server가 metrics.k8s.io 그룹의 API를 직접 구현하고 있고,
apiserver가 그걸 aggregation해서 노출해주는 거예요.
📌 NodeMetrics vs PodMetrics 구조 차이

usage 필드에서 cpu, memory 등 노드 전체 사용량을 나타내고,
timestamp에서 수집 시각을 나타내며 window는 수집 윈도우를 의미합니다.
* 노드 단위라서 container 필드가 없네요.
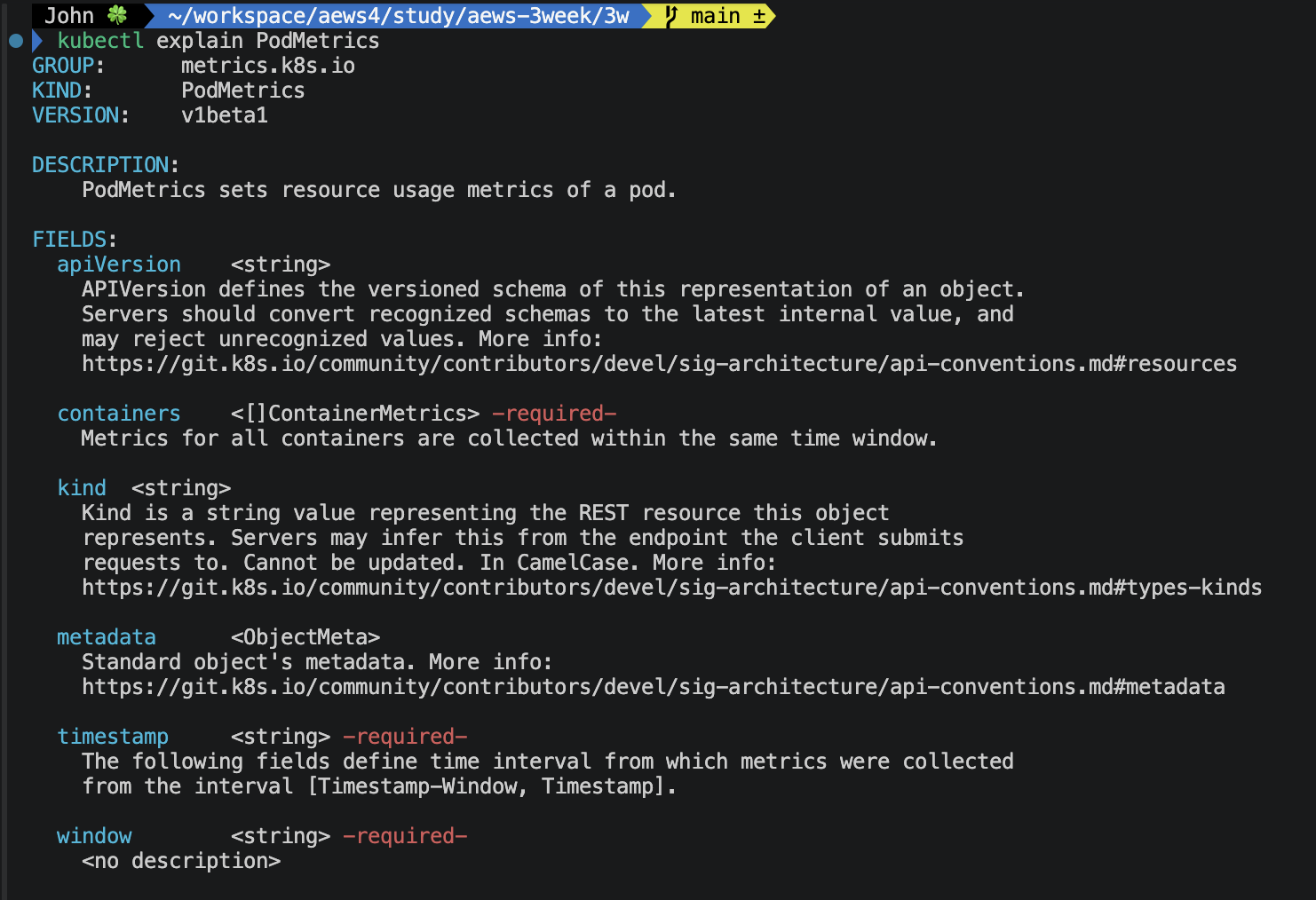
container에서 컨테이너 별 사용량을 배열합니다 (안에 usage 필드가 있음)
파드 안의 컨테이너별로 쪼개서 보여줘요. `kubectl top pods --containers` 가 가능한 이유입니다.
노드 / 파드 cpu,mem 자원 시용 확인

1) Pods CPU 자원 사용량 분석
- aws-node (kube-system) : VPC CNI 데몬셋 파드라 네트워크 처리를 계속 하고 있으므로 가장 높음.
- metrics-server (kube-system) : 15초마다 kubelet 스크레이핑하니까 의외로 CPU를 꽤 쓰네요.
- coredns, kube-proxy (kube-system) : 요청이 없으면 잘 사용하지 않아서 가장 낮습니다.
2) Pods Memory 자원 사용량 분석
- aws-node (kube-system) : VPC CNI는 노드당 ENI/IP 상태를 메모리에 들고 있어서 높아요.
- metrics-server (kube-system) : 아까 limit이 400Mi였는데 실제론 18Mi만 써요. 여유 많음.
- coredns, kube-proxy (kube-system) : 요청이 없으면 잘 사용하지 않아서 낮네요. 경량.
external-dns 정보 확인

Deployment, Pods 상태 확인 (metrics-server와 달리 replica 1개네요)
ExternalDNS는 Route 53 레코드를 관리하는데,
여러 개가 동시에 돌면 레코드 충돌이 날 수 있어서 단일 인스턴스가 일반적이에요.
7979 포트는 ExternalDNS의 메트릭/헬스체크 포트예요
/healthz , /metrics 엔드포인트를 여기서 제공해요. 외부 트래픽을 받는 게 아니라 모니터링용입니다.
Describe 해서 확인해보겠습니다.

StrategyType 필드가 Recreate
metrics-server는 RollingUpdate 였는데 external-dns는 Recreate 입니다.
ExternalDNS가 두 인스턴스가 동시에 뜨면 같은 Route 53 레코드를 동시에 수정하다가 충돌할 수 있어서,
업데이트 시 기존 파드를 완전히 죽인 뒤 새 파드를 띄우는 방식을 택한 것 입니다.
Args 필드
--source=service , --source=ingress는 두 소스를 모두 감시해요.
둘 중 하나에 external-dns 어노테이션이 붙으면 Route 53 레코드를 자동 생성합니다.
--policy=upsert-only는 create/update는 하지만 delete는 안 합니다.
실수로 레코드가 지워지는 걸 방지하는 안전장치예요. 다만, --policy=sync 로 바꾸면 삭제도 자동으로 됩니다.
--registry=txt는 ExternalDNS가 본인이 만든 레코드를 추적하기 위해 TXT 레코드를 같이 생성합니다.
--txt-owner-id=myeks 는 이 클러스터가 만든 레코드임을 표시하는 식별자예요.
멀티 클러스터 환경에서 서로 다른 클러스터가 같은 Route 53을 쓸 때 레코드 소유권 충돌을 방지합니다.
--interval=1m는 1분마다 Service/Ingress를 폴링해서 Route 53과 싱크합니다.

Limits, Requests 필드
metrics-server(100m cpu, 200Mi memory)보다 훨씬 가볍네요?
Route 53 API를 1분 간격으로 호출하는 게 전부라서 상시 부하가 거의 없는 것 같습니다.
Liveness, Readiness Probe 설정
Liveness는 2번 실패하면 바로 재시작해요. Readiness는 6번 실패해야 트래픽에서 제외됩니다.
ExternalDNS 입장에선 Route 53 API 응답이 잠깐 느려도 파드를 트래픽에서 빼면 안 되니까
Readiness를 더 관대하게 잡은 것 같습니다.
03. external-dns 배포 시 --policy=sync 적용
위에서 external-dns의 add on 파드의 기능을 describe로 확인하였을 때,
args 필드에서 "--policy=upsert-only"로 되어 있던 것을 확인할 수 있습니다.
--policy=sync 아규먼트로 수정을 하면, Service/Ingress를 삭제했을 때 Route 53 레코드도 같이 정리되겠네요.
📌 Terraform 코드 수정

external-dns 부분에서 extraArgs의 필드 값을 위 사진과 같이 변경하시면 됩니다.
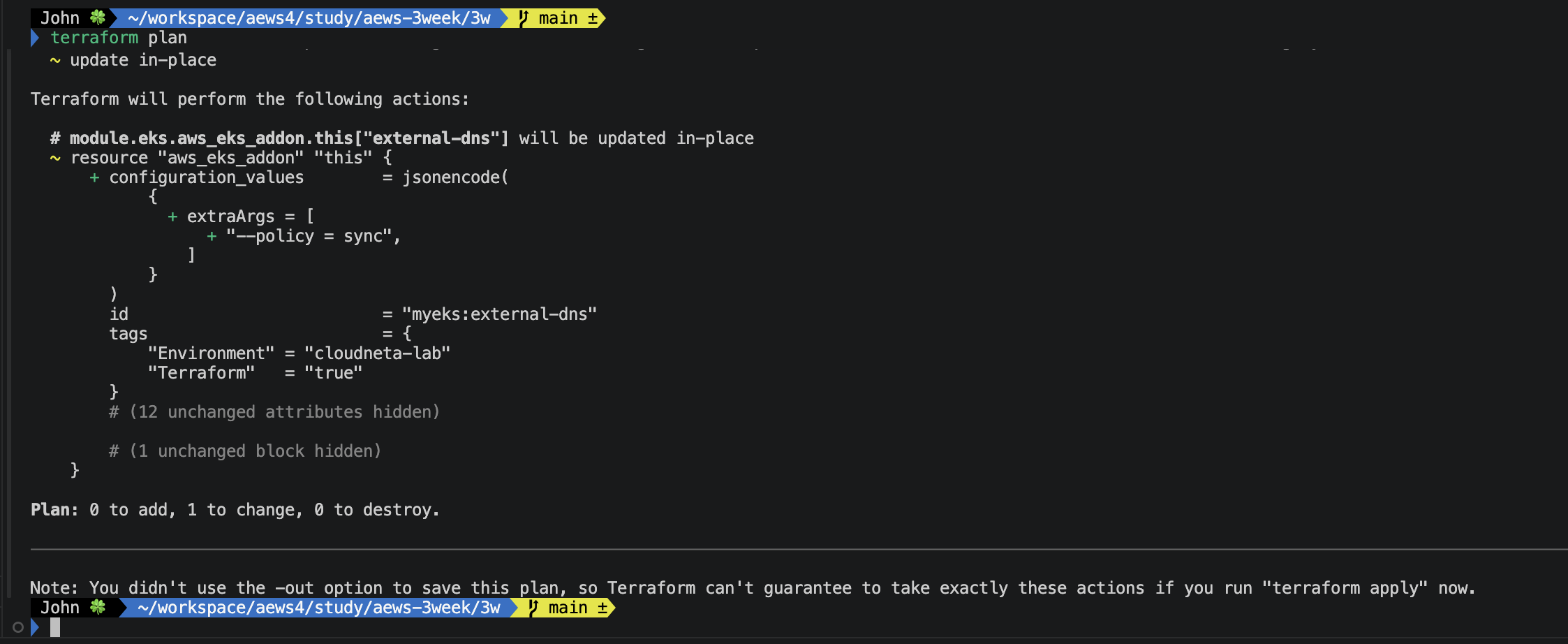
변경사항이 있으니 terraform init으로 초기화 후 plan으로 확인하시어 문제가 없다면 apply !
apply시 에러가 생기신 분들은 아래 '더보기'를 클릭하시어 확인해주세요.
참고로, 실습 도중에 해당 애드온의 아규먼트를 "--policy = sync"로 변경해서 terraform apply 하면 에러납니다.
kubectl get pod -n external-dns 해서 확인해보면 CrashLoopBackOff 상태이고,
descrirbe로 찍어보면 뭔가 기존 "--policy=upsert-only" 설정과 충돌하고 있는 것으로 보였습니다.
처음부터 아규먼트 값을 "--policy = sync" 이렇게 하면 상관 없습니다만 저처럼 실습 도중 변경하는 것이라면
external-dns = {
most_recent = true
configuration_values = jsonencode({
policy = "sync"
})
}
이렇게 생성하시게 되면 에러 없이 파드도 잘 올라올 것입니다.

잘 올라온 것을 확인하실 수 있습니다.
📌 테스트용 서비스 생성
# test-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: test-external-dns
namespace: default
annotations:
external-dns.alpha.kubernetes.io/hostname: test.ssunghwan.cloud
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80해당 yaml파일을 kubectl 명령으로 apply !
Route53 레코드 생성 확인
# 1분 기다린 후 (--interval=1m)
aws route53 list-resource-record-sets \
--hosted-zone-id Z10185601323T2GYM6HLE \
--query "ResourceRecordSets[?contains(Name, 'test')]"A 레코드 + TXT 레코드 두 개가 생기면 정상입니다.

레코드가 잘 생성된 것을 확인하실 수 있습니다. 로그도 찍어볼까요?

AAAA 레코드는 ipv6 형태여서 제외하면 A, TXT 레코드 2개가 정상적으로 올라왔습니다.
(기본적으로 ALB는 ipv4, ipv6 듀얼스택을 지원해서 AAAA도 생성된 것입니다)
이제 지워볼까요 ? 이번엔 가독성을 위하여 AWS Console에서 확인해보겠습니다.

약 30초 내외로 바로 삭제가 되는 것을 확인하실 수 있습니다.
긴 글 읽어주셔서 감사합니다.
다음 포스팅에서는, 프로메테우스 및 그라파나 같은 모니터링 도구에 대해 소개드릴 예정입니다.