Introduction to EKS

안녕하십니까.
CloudNet@ 팀 'Gasida' 님이 진행하시는 스터디 내용 중,
EKS에 대해서 소개하는 내용을 정리해보았습니다.

EKS (Elastic Kubernetes Service) 란?
AWS의 관리형 Kubernetes Service 입니다.
- Managed 하게 AWS에서 직접 Control Plane을 운영해주며 고객이 신경을 쓰지 않아도 되는 장점이 있다.
- Kubernetes 클러스터의 구축, 보안 및 유지 관리를 간소화할 수 있습니다.
- 자체 데이터 센터를 유지 관리하는 것보다 피크 수요를 충족할 수 있도록 충분한 리소스를 제공한다.
핵심은 Control Plane / Data Plane의 분리입니다.
- Control Plane : API, Etcd, Scheduler 서버가 있습니다.
- Data Plane : 워크로드가 직접 실행되는 Node를 의미하며 서비스를 동작하는 Pods를 의미한다.
- 서비스를 동작하는 Pods에는? kube-proxy, core-dns, CNI etc..
앞서 말씀 드렸듯, EKS의 표준은 기본적으로 control plane을 AWS에서 관리하는 것입니다.
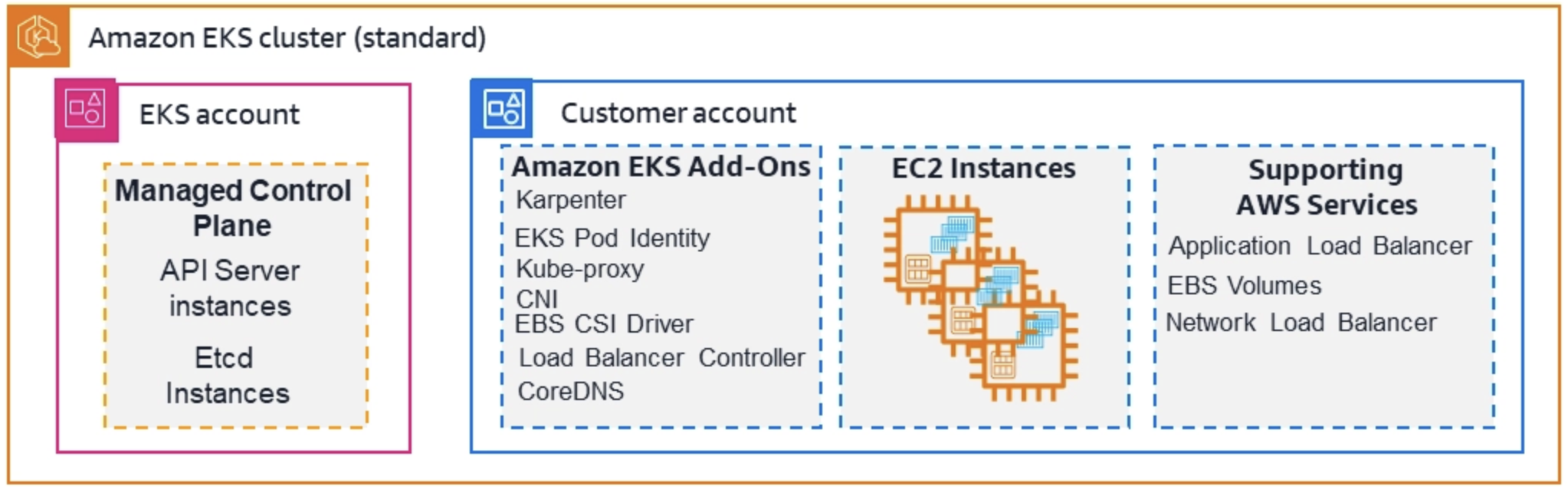
→ 실제로 운영한다면, 고객이 data plane만 신경쓰고 운영하면 되서 부담이 적습니다.
📌 EKS Standard
- EKS를 생성할 때 AWS가 컨트롤 플레인을 관리합니다. (실제 운영 환경에서도 보이지 않음)
- 노드 관리, 워크로드 스케줄링, AWS 서비스 연동, 컨트롤 플레인 상태 저장 및 확장 등 클러스터 가용성을 유지하는 데 필요한 핵심 작업들이 자동으로 처리됩니다.
하지만? AWS에서 Data Plane도 관리하도록 제어를 확장하는 모드가 존재합니다!

📌 EKS Auto Mode
- 컨트롤 플레인을 넘어 데이터 플레인(노드)까지 AWS가 직접 관리하는 모드입니다.
- 컴퓨팅 인스턴스 선택, 인프라 프로비저닝, 리소스 동적 스케일링, 비용 최적화, OS 패치, 보안 서비스 연동까지 인프라 운영 부담을 대폭 줄이고 애플리케이션 개발에만 집중할 수 있도록 설계되었습니다.
1-1. EKS Node Mode 3가지
EKS를 관리하기 위한 노드 모드 3가지는 아래와 같습니다.
- Self-managed (EC2 직접 관리) : AMI 직접 선택, 완전한 OS제어, 커스텀 커널, 스케일링 수동, 패치 직접 관리의 특징을 가지고 있으며 운영 부담이 높고 유연성이 뛰어납니다.
- Managed Node Group (AWS 반자동 관리) : 자동 프로비저닝 및 노드 업데이트, Auto Scaling 내장, 커스터마이징 제한의 특징을 가지고 있으며 균형 잡힌 모드여서 많은 고객사에서 사용 중입니다.
- AWS Fargate (완전 Serverless) : 노드 관리 불필요, Pods 단위 과금, 완전 격리 보안, Daemonset 불가 등 특징을 가지고 있으며 완전 관리형이다 보니 운영 부담이 없고 소규모(개발환경)에 유리합니다.
각 환경에 맞게 사용되는 모드 3가지를 소개해드렸는데 대부분의 프로덕션 환경에서는
'Managed Node Group'을 사용할 것으로 보입니다.
Self-managed는 GPU 드라이버나 커스터마이징이 많이 필요한 특수한 커널 모듈이 필요할 때,
Fargate는 배치 잡이나 격리가 중요한 워크로드에 사용됩니다.
1-2. EKS 핵심 컴포넌트 로드맵

✅ Control Plane
사용자(Admin)가 직접 건드릴 일 없는 영역 즉, AWS 완전 관리형으로 제공이 되며
AWS가 Multi-AZ로 이중화해서 운영하며 거의 완벽한 SLA를 보장합니다.
- API Server : 모든 kubectl 명령과 내부 컴포넌트 통신의 중심이며, REST API로 클러스터 상태를 읽고 씀.
- ETCD : 클러스터의 모든 상태 데이터를 저장하는 분산 키-값 스토어. "지금 Pod가 몇 개 있고, 어느 노드에 있는지" 같은 정보가 여기 들어있습니다.
- Scheduler : 새로운 Pod가 생성될 때 어느 노드에 배치할지 결정합니다. 리소스 여유, affinity 규칙, taint/toleration 등을 고려합니다.
- Controller Manager : Deployment, ReplicaSet 등 다양한 컨트롤러를 실행하며 "선언한 상태"와 "실제 상태"가 일치하도록 지속적으로 조정합니다. (API Server를 통해 etcd의 상태를 읽고 조정하는 프로세스)
✅ Data Plane
클러스터가 동작하기 위한 기본 구성 요소들로, AWS가 버전 업데이트와 패치를 관리합니다.
- Core DNS : 클러스터 내부 DNS 서버. my-service.default.svc.cluster.local 같은 서비스 이름을 IP로 변환합니다.
- Kube-proxy : 각 노드에서 실행되며 Service의 네트워크 규칙(iptables/IPVS)을 관리합니다. 또한, Pod 간 트래픽 라우팅을 담당합니다.
- Kubelet : 노드에서 실행되며 API Server와 통신하고, Pod 스펙을 받아서 컨테이너를 실제로 기동/유지합니다.
- Container Runtime : kubelet의 지시를 받아 실제로 컨테이너를 실행하는 레이어입니다
- VPC CNI : EKS 고유의 네트워크 플러그인. Pod에 실제 VPC IP를 직접 할당해서 AWS 서비스와 오버레이 없이 바로 통신할 수 있게 합니다.
02. Kubernetes 배포 단위 : Pods
📌 Pods 란?
Kubernetes에서 배포와 실행의 최소 단위는 컨테이너가 아니라 Pod입니다.
- Pod는 하나 이상의 컨테이너를 감싸는 논리적 호스트
- 같은 Pod 안의 컨테이너들은 네트워크 네임스페이스와 스토리지 볼륨을 공유
- 즉, localhost로 서로 통신하고 같은 볼륨을 마운트할 수 있습니다.
Pod 하나에 컨테이너를 여러 개 넣는 패턴을 사이드카(sidecar)라고 부릅니다. 앱 컨테이너 옆에 로그 수집기나 Envoy 프록시를 붙이는 방식이 대표적입니다.
위 컴포넌트 로드맵을 참고해 보았을 때 Pods가 실제로 실행되기 까지의 과정은 아래와 같습니다.
- API Server가 요청을 받아 etcd에 저장합니다.
- Scheduler가 조건(리소스 여유, affinity, taint/toleration)을 따져 실행할 노드를 결정하고, 결과를 etcd에 씁니다.
- 해당 노드의 kubelet이 API Server를 폴링하다가 자신에게 바인딩된 Pod를 감지
- kubelet이 containerd(컨테이너 런타임)에 컨테이너 생성을 지시합니다.
- containerd가 ECR에서 이미지를 pull하고 컨테이너를 기동합니다. → 이미지 저장 방식에 따라 상이함.
- kubelet이 컨테이너 상태를 주기적으로 확인하고 API Server에 보고합니다.
kubelet은 컨테이너 런타임과 CRI(Container Runtime Interface) 표준으로 통신합니다.
EKS는 기본적으로 containerd를 사용하며, Docker는 1.24부터 기본 런타임에서 제외됐습니다.
2-1. Pods 배포 유형
📌 상태 비저장 어플리케이션 (Deployment, ReplicaSet)
- 웹 서버, API 서버처럼 세션 데이터를 로컬에 저장하지 않는 어플리케이션에서 사용합니다.
- Deployment가 ReplicaSet을 관리하고, ReplicaSet이 Pod 수를 유지합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
app: api
template:
metadata:
labels:
app: api
spec:
containers:
- name: app
image: 123456789.dkr.ecr.ap-northeast-2.amazonaws.com/api:1.0.0
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
replicas: 3을 선언하면 Controller Manager가 항상 3개를 유지하며, Pod가 하나 죽으면 즉시 새 파드를 생성함.
RollingUpdate 전략으로 무중단 배포가 가능하고, HPA와 연동하면 트래픽에 따라 replicas가 자동 조정된다.
📌 상태 저장 어플리케이션 (StatefulSet)
- 데이터베이스, 메시지 큐처럼 Pod마다 고유한 ID와 영구 스토리지가 필요한 경우 씁니다.
Deployment와의 핵심 차이는 세 가지입니다.
- Pod 이름이 mysql-0, mysql-1처럼 순서가 보장된 고정 이름을 갖습니다. (재시작 시 같은 이름 유지)
- 각 Pod에 개별 PersistentVolumeClaim이 붙어 Pod가 재스케줄링되더라도 같은 데이터를 바라봅니다.
- 셋째, 기동과 종료 순서가 보장됩니다(mysql-0 기동 완료 후 mysql-1 기동).
EKS에서는 EBS CSI Driver와 함께 주로 사용하며, ReadWriteOnce 특성상 같은 AZ 내 노드에 스케줄링되도록
affinity를 설정하는 것이 일반적입니다.
📌 노드별 어플리케이션 (DaemonSet)
- 클러스터의 모든 노드(또는 특정 노드)에 Pod를 하나씩 실행합니다.
- 노드가 추가되면 자동으로 해당 노드에도 Pod가 배포됩니다.
데몬셋을 사용하는 대표적인 사례는 아래와 같습니다.
- 로그 수집 에이전트 (Fluent Bit → CloudWatch / OpenSearch)
- 노드 메트릭 수집 (Prometheus node-exporter)
- 네트워크 플러그인 (VPC CNI, kube-proxy 자체가 DaemonSet)
- 보안 에이전트 (GuardDuty 런타임 에이전트)
참고로 위에서 말씀드렸다 싶이 Fargate 환경에서는 데몬셋 구성이 불가능하여
로그 수집이 필요한 경우에는 Sidecar 방식으로 구성해서 사용해야 합니다.
▣ 워크로드 선택 기준 요약
| 상황 | 컨트롤러 |
| 웹 서버, API, 마이크로서비스 | Deployment |
| DB, Kafka, Elasticsearch | StatefulSet |
| 로그 수집, 모니터링 에이전트 | DaemonSet |
| 데이터 마이그레이션, 배치 처리 | Job |
| 정기 리포트, 주기적 정리 작업 | Crontab |