Chapter 12. Docker Swarm cluster 구성

안녕하세요,
오늘은 Cluster를 구성하고,
실제 운용을 해보는 시간을 갖도록 하겠습니다.

01. Docker Swarm init
일단 구성하기에 앞서, 실습 Virtual machines을 복제하여 2개의 worker까지 만들어 두고 시작합시다!

이제 worker들이 구성이 되었다면 각자의 서버에 로컬 DNS를 등록해주는 작업을 선행합시다.
각자 실제 본인들의 hostOS IP를 적어주시면 되고, swarm 구성 시 연동할 때 필요합니다!
vi /etc/hosts
192.168.56.100 master
192.168.56.101 worker-web
192.168.56.102 worker-was
✅ 초기화 (init)
- Manager 역할을 수행 할 Host OS에서 아래와 같은 명령어를 입력하여 swarm join token을 발급받기.
- worker들이 manager에게 join할 때 token 인증 방식으로 join하게 됩니다!
docker swarm init --advertise-addr 192.168.56.100
이제 해당 token을 worker node에 붙혀넣으시면 아래와 같이 확인할 수 있습니다.

📌 docker swarm port number
root@master:~# sudo netstat -tulnp | grep dockerd
tcp6 0 0 :::2377 :::* LISTEN 2157/dockerd
tcp6 0 0 :::7946 :::* LISTEN 2157/dockerd
udp6 0 0 :::7946 :::* 2157/dockerd자, 여기서 알 수 있는 부분은 docker swarm은 기본적으로 2377 port를 사용하게 된다는 점 입니다.
추가적으로 node간 통신은 7946 tcp/udp port를 사용하고 ingress overlay network는 4789 udp port를 사용합니다.
docker swarm에 대한 정보를 알고 싶으면 'docker info'를 통해 알 수 있으나, 아래와 같이 필터링 해보자.

02. Swarmpit - 모니터링 도구
✅ Swarmpit 개요 & 특징
- Docker Swarm 클러스터를 위한 경량 웹 기반 관리 및 모니터링 도구
- Docker Swarm API를 직접 사용하여 클러스터와 통신
- 별도의 에이전트 설치가 필요없고, Swarm의 기본 기능만으로 동작합니다.
- overlay 네트워크, secrets, conflags 등을 모두 네이티브 하게 지원합니다.
- 실시간으로 노드별 CPU, Memory, Disk 사용량 등 시각화 하여 직관적으로 확인이 가능함.
즉, Swarm 수준에서 모든 기능을 완벽하게 지원하며 경량화된 모니터링 도구라는 것이 Point!
✅ Swarmpit 구성
- Swarmpit은 4개의 서비스로 구성되며 하나의 Stack으로 동작하게 된다.
1) swarmpit_app (핵심 애플리케이션)
- Swarmpit의 백엔드 API 서버이자 웹 UI 제공 컨테이너
- Clojure로 작성된 백엔드 + React로 작성된 프론트엔드가 함께 포함됨
- Docker Swarm API와 직접 통신하여 클러스터 제어
📌 app의 구체적인 동작
/var/run/docker.sock을 마운트하여 Docker Engine API에 직접 접근
Manager 노드에서만 실행되어야 함 (Swarm 관리 권한 필요)
CouchDB에서 사용자 계정, 레지스트리 설정 등을 읽어옴
InfluxDB에서 메트릭 데이터를 조회하여 그래프 생성
사용자가 "서비스 생성" 버튼을 누르면 → Docker API 호출 → docker service create 실행
2) swarmpit_agent (메트릭 수집기)
- 각 노드의 리소스 사용량을 수집하는 경량 에이전트
- CPU, 메모리, 네트워크, 디스크 I/O 등의 메트릭 수집
📌 agent의 구체적인 동작
각 노드에서 실행 (global mode)
docker.sock을 통해 해당 노드의 컨테이너 정보 수집
실시간 리소스 사용량을 계산
InfluxDB로 메트릭 전송 (HTTP POST)
약 5초마다 반복
3) swarmpit_db (CouchDB - 설정 저장소)
- Swarmpit의 영구 설정 데이터 저장
- NoSQL 문서 기반 데이터베이스 (JSON 형태)
Why CouchDB를 사용할까?
경량이면서도 안정적인 문서 DB
복제와 동기화가 쉬워 추후 HA 구성 가능
JSON 기반이라 JavaScript/Clojure와 궁합이 좋음
4) swarmpit_influxdb (시계열 메트릭 DB)
- 시계열 메트릭 데이터 전문 저장소
- Agent가 수집한 모든 성능 지표를 저장
Why influxdb를 사용할까?
시계열 데이터 처리에 최적화 (시간 기반 쿼리가 매우 빠름)
자동 데이터 압축 및 보관 정책 (Retention Policy)
Grafana처럼 시간대별 쿼리를 효율적으로 처리
📌 Docker swarmpit traffic flow
- Agent (각 노드) → HTTP POST → InfluxDB (저장)
- Swarmpit App (UI) → HTTP GET → InfluxDB (조회)
- 그래프로 시각화
2-1. Swarmpit install
✅ 설치 명령어
docker run -it --rm \
--name swarmpit-installer \
--volume /var/run/docker.sock:/var/run/docker.sock \
swarmpit/install:edge
- swarmpit을 구성할 때 초기에 기본적으로 입력해야 할 정보들이 있습니다.
- stack name, application port, volume driver등이 있는데 저는 실습용이므로 모두 default를 사용함.
현재 테스팅 용이므로 간단하게 설치하는 방식으로 진행하지만,
현업 권장 사항으로는Docker compose 파일로 직접 설치하는 방식이 권장된다.
# 공식 docker-compose.yml 다운로드
curl -L https://raw.githubusercontent.com/swarmpit/swarmpit/master/docker-compose.yml -o swarmpit.yml
# 내용 확인
cat swarmpit.yml
# 바로 배포
docker stack deploy -c swarmpit.yml swarmpit
📌 swarmpit이 잘 생성되었는지 swarm 명령으로 확인
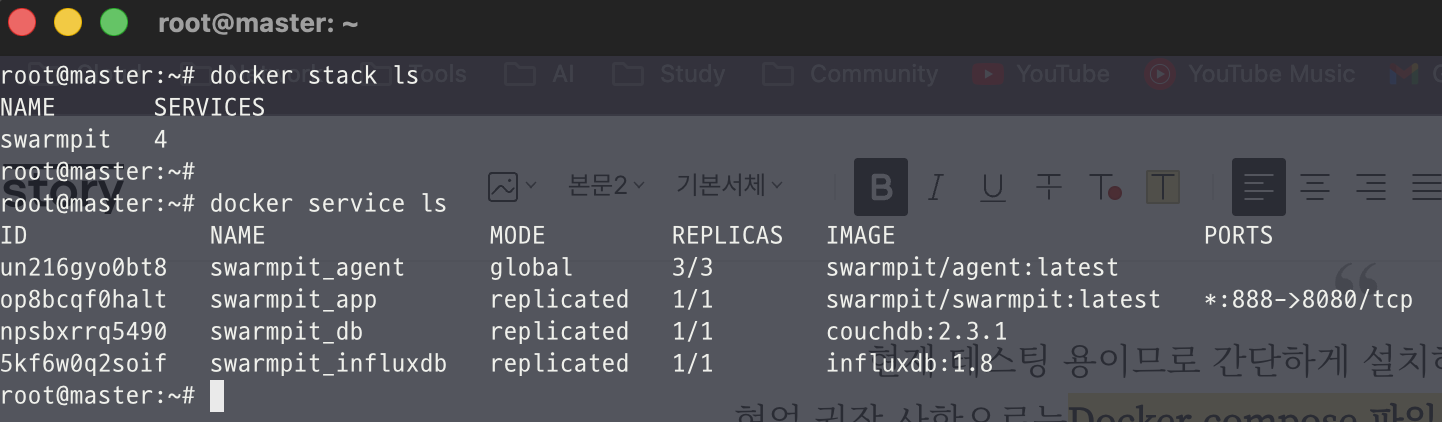
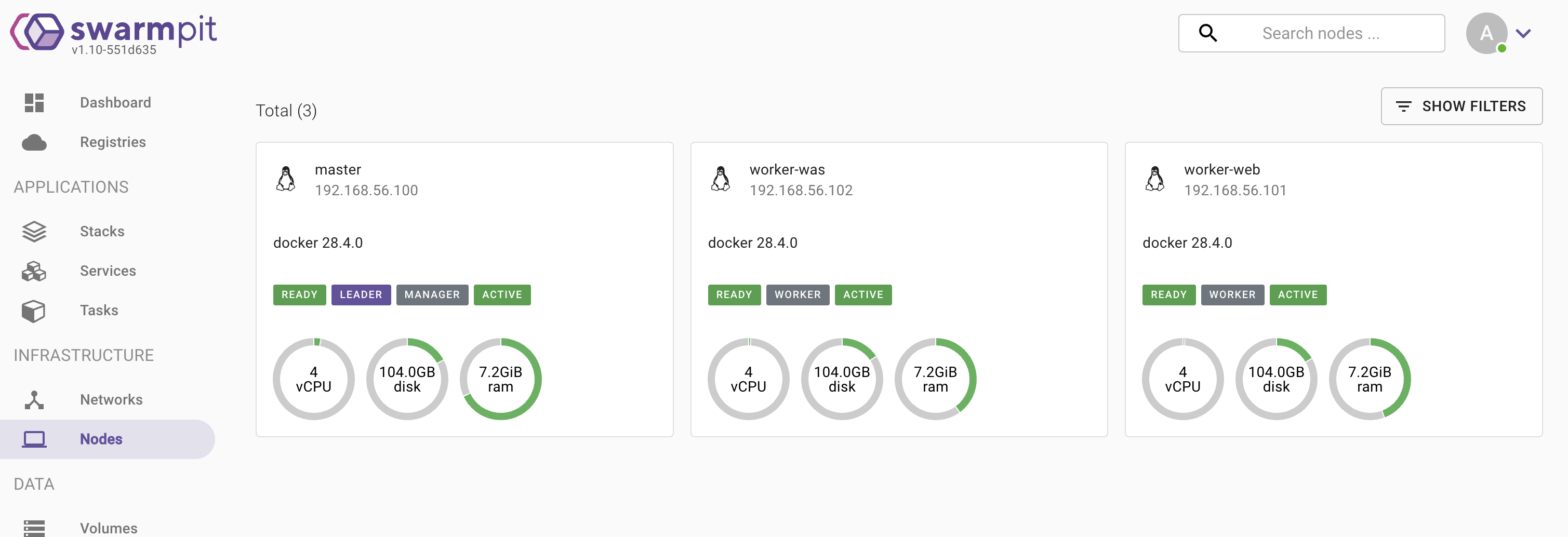
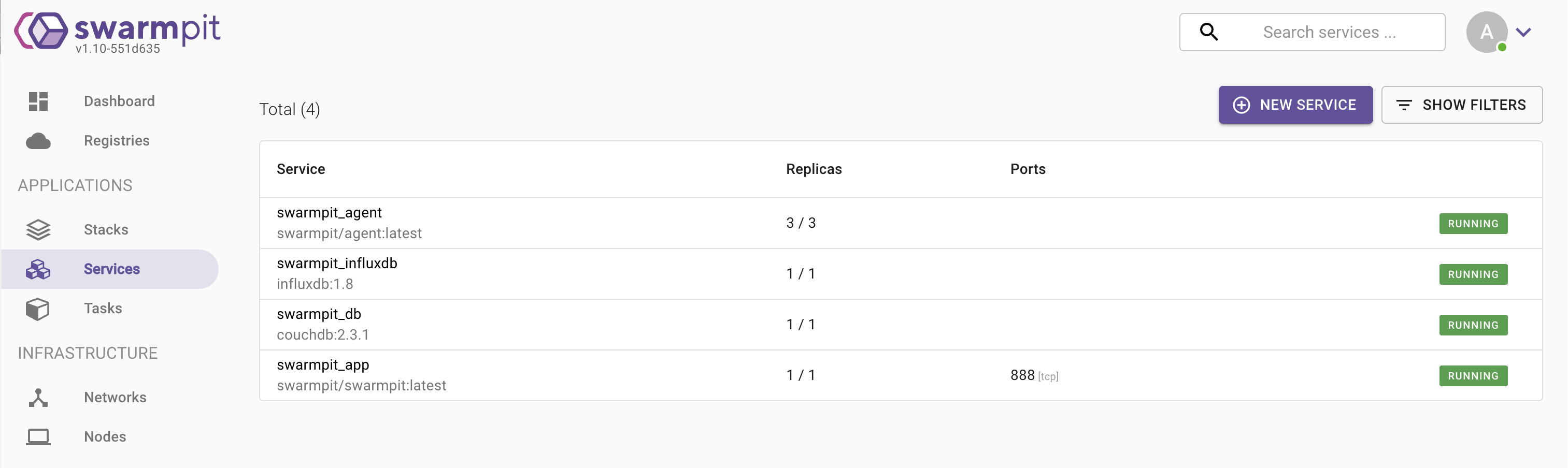
03. Swarm cluster 주요 기능
✅ Rolling Update
- Cluster를 활용하여 Service를 배포하였을 때 Task에 대한 Version을 업데이트 해야 하는 경우 사용됨.
- 기본적으로 새 Task를 생성하고 새 Task에서 Version Update가 완료가 되었을 때 기존 Task를 삭제함.
- 이 기능은 default이며, 기존 Task를 삭제 후 새 Task를 생성하여 업데이트 하는 옵션도 있음.
1) Service 배포
docker service create --name rolling_web --replicas 3 nginx:1.24-alpine
2) Rolling Update
docker service update rolling-web --image [새 Image 버전]
- service 프로세스를 확인해보면 1.24에서 1.25버전으로 업데이트 확인.
- 이 업데이트의 과정을 모니터링 도구로 활용을 해서 직접 확인까지 해보는 것도 좋은 방법입니다.
그렇다면, 반대로 에러가 발생하였을 경우 이전 Version으로 되돌려야 겠죠?
3) Rollout
docker service rollback rolling_web
- 현재 프로세스를 확인하였을 때 다시 1.24 버전으로 돌아온 것을 확인할 수 있다.
Docker Swarm Update Options
--update-parallelism : 한 번에 업데이트할 태스크(컨테이너) 수를 지정한다. (default : 1)
--update-delay [duration] : 각 배치(또는 태스크) 업데이트 사이의 지연 시간을 지정한다.
--update-failure-action [pause|continue|rollback] : 업데이트 중 실패 발생 시 동작을 지정한다. (default : pause)
--update-order [stop-first|start-first] : 업데이트의 작동 순서를 지정. (default : stop-first)
만약, Hardware의 유지보수로 인해 Node에 대한 업데이트가 이루어져야 한다면?
# drain
docker node update --availability drain [node 이름]
# active
docker node update --availability active [node 이름]
명령을 통해서 drain을 적용한다면, 해당 node에서 동작하는 Task들이 다른 Node로 옮겨간다.
여기서 주의해야할 점은 해당 node의 업데이트가 완료가 되어 다시 Active 상태가 되어도,
이미 drain된 Task들에 대해 rebalance 되지 않고 유지가 된다.
* 그렇다면 나중에 Rolling update를 진행하거나 Service에 대한 Scaling을 조절한다면
노드 간 균형이 맞춰지므로 유의하여 작업을 진행하면 되겠습니다.
04. Swarm Stack
✅ Stack 이란?
위에서 활용해보았던 Docker swarmpit을 예로 들자면, swarmpit은 4개의 Service를 하나의 Stack으로 배포한다.
그렇다면.. Stack은?
- 여러 노드로 구성된 클러스터 환경에서 서비스를 통해 컨테이너 애플리케이션을 배포.
- 즉, yaml 코드를 활용(compose 기술)하여 swarm 클러스터 노드에 연결된 컨테이너 서비스를 실행한다.
compose를 통해 배포를 하게된다면 단일 호스트에서만 실행이 되는데,
stack을 통해서 다중 호스트에 여러 Task를 배포할 수 있습니다.
4-1. [Service Deploy] 웹서버 부하분산
Docker Swarm Cluster로 4개의 Task를 배포하도록 구현을 할건데, 아래와 같은 규칙이 있다.
- manager node에 HAproxy를 구현하여 Task에 로드밸런싱
- 하나의 Stack으로 구현하여 worker node 2개에 각각 2개의 Task가 동작하도록 구성.
📌 haproxy.cfg & yaml 파일 작성
1. haproxy.cfg
global
log stdout format raw local0
maxconn 4096
defaults
mode http
log global
option httplog
option dontlognull
timeout connect 5s
timeout client 30s
timeout server 30s
frontend fe_http
bind *:80
default_backend be_nginx
backend be_nginx
balance roundrobin
option httpchk GET /
http-check expect status 200
server nginx-vip nginx:80 check
2. service yaml 파일 작성
configs:
haproxy_cfg:
file: ./haproxy.cfg
services:
nginx:
image: nginx:1.25.0-alpine
deploy:
replicas: 4
placement:
constraints:
- node.role != manager
restart_policy:
condition: on-failure
max_attempts: 3
environment:
SERVICE_PORTS: 80
networks:
- haproxy-web
proxy:
image: haproxy:2.9-alpine
depends_on:
- nginx
ports:
- "80:80"
networks:
- haproxy-web
deploy:
mode: global
placement:
constraints:
- node.role == manager
configs:
- source: haproxy_cfg
target: /usr/local/etc/haproxy/haproxy.cfg
mode: 0444
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
haproxy-web:
external: true
📌 docker network 생성
docker network create --driver overlay --attachable haproxy-web
# docker network ls
NETWORK ID NAME DRIVER SCOPE
oi0ykry8gr6y haproxy-web overlay swarm
📌 확인 & 배포
docker stack deploy --compose-file haproxy-web-stack.yaml haproxy-web
📌 로드밸런싱 확인
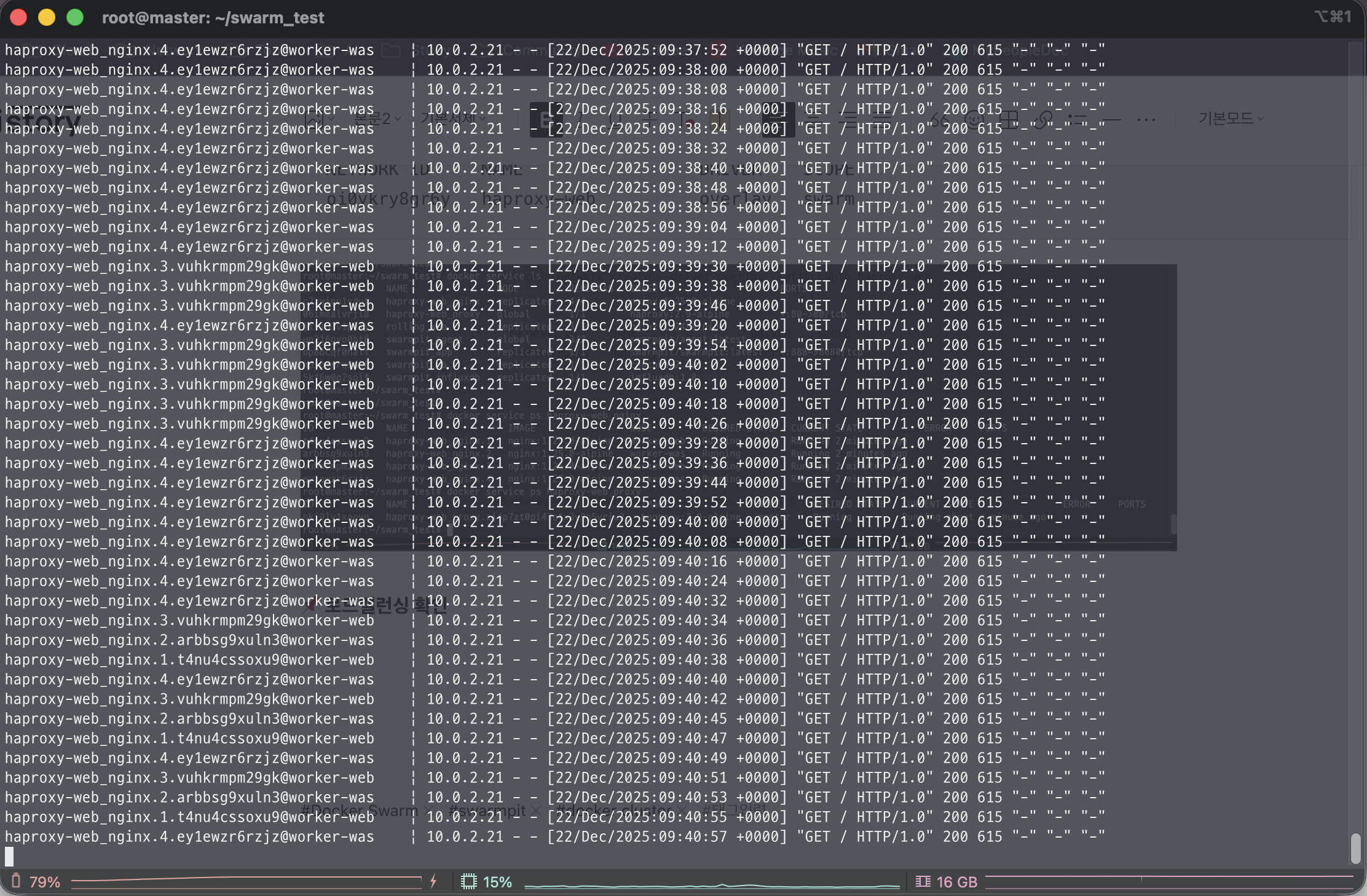
- 현재 Health check를 라운드로빈 형태로 분산 Check를 하고 있음 → HA Proxy
즉, Docker swarm의 기능중에 Ingress Network 기능을 통해서 Task에 Routing Mesh가 되고
IPVS 기능을 통해 스웜에서 발생한 트래픽 분산을 노드에서 실행되는 Task에 분산해준다.
+ 스웜은 IPVS 기능을 통해 LB 기능이 내장되어 있는데 왜 HA Proxy를 사용했을까?
- HAProxy를 따로 사용한 이유는 URL 기반 L7 레이어를 라우팅 해주기 위해.
- IPVS 기능은 L4 (TCP/IP) 레이어의 라우팅 담당임.
여기까지 Docker swarm에 대해 알아보았습니다.
감사합니다 :)